 MySQL深入20-这么保证数据不丢
MySQL深入20-这么保证数据不丢
# MySQL深入20-这么保证数据不丢
只要redo log和bin log保证持久化到磁盘,就能确保MySQL异常重启后,数据可以恢复。本文就对redo log和bin log写入流程进行详情分析。
# bin log的写入机制
bin log的写入逻辑:事务执行过程中,先把日志写到binlog cache,事务提交的时候,再把bin log cache写到bin log文件中。
一个事务的binlog是不能被拆开的,因此无论这个事务多大,也要确保一次性写入。
系统给每个线程分配了一片binlog cache内存。参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
事务提交的时候,执行器把binlog cache里完整的事务写入binlog中,并清空binlog cache。
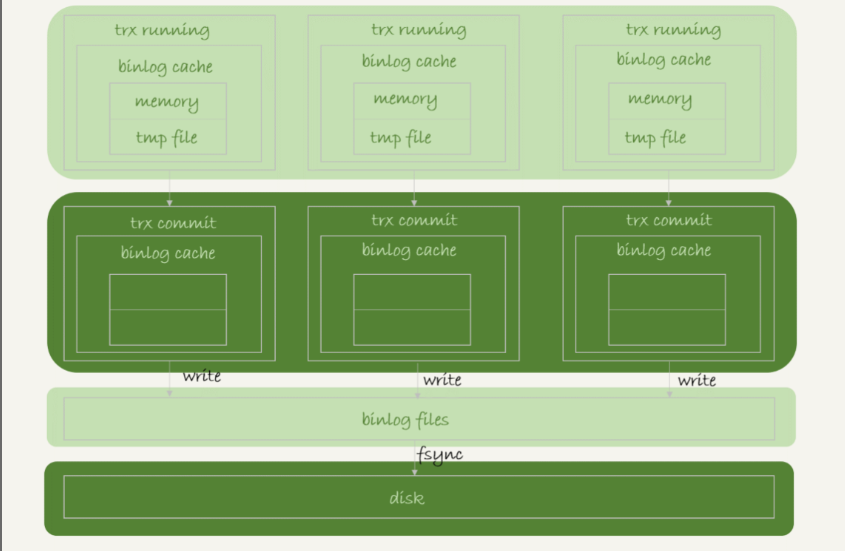
由上图可以看到每个线程有自己binlog cache,但是共用同一份binlog文件:
- 图中的 write,指的就是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快。
- 图中的 fsync,才是将数据持久化到磁盘的操作。一般情况下,我们认为 fsync 才占磁盘的 IOPS。
write和fsync的时机,是由参数sync_binlog控制的:
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
因此在IO瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性能。但是也存在一个问题,如果主机发生异常重启,那么会丢失最近N个事务的binlog日志。
# redo log的写入机制
事务在执行过程中,生成的redo log是要先写到redo log buffer的。但是redo log并非每次生成后要直接持久化到磁盘。
如果事务执行期间 MySQL 发生异常重启,那这部分日志就丢了。由于事务并没有提交,所以这时日志丢了也不会有损失。
但是在事务还没提交的时候,redo log buffer中的部分日志是有可能被持久化到磁盘的。
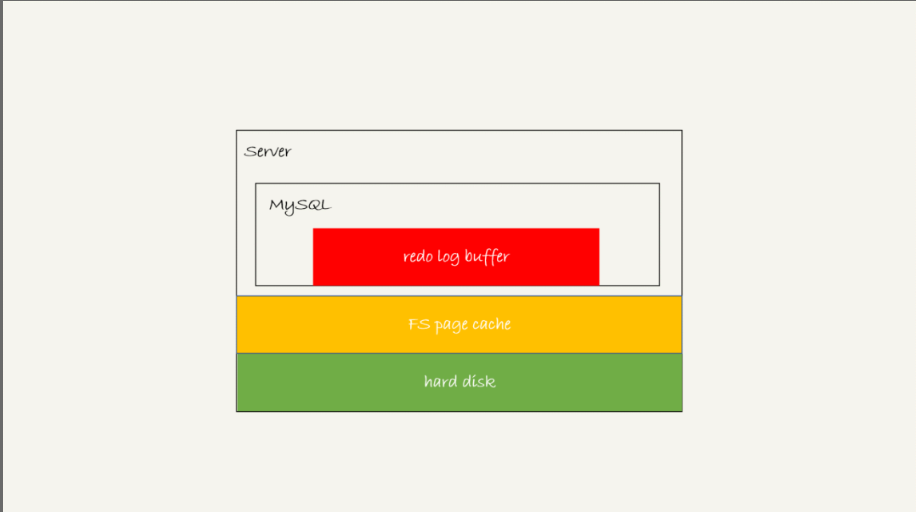
存在redo log buffer中,物理是在MySQL进程内存中,图中红色部分。
写到磁盘(write),但是没有持久化(fsync),物理上是在文件系统中的page cache里面,也就是图中黄色部分。
持久化到磁盘,对应的是hard disk,对应图中绿色部分。
那么日志写到 redo log buffer 是很快的,wirte 到 page cache 也差不多,但是持久化到磁盘的速度就慢多了。
redo log的写入策略是由innodb_flush_log_at_trx_commit参数进行设置的:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;该策略不管是主机掉电还是MySQL异常重启,都有丢数据的风险,风险高,但是写入快
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;该策略直接写到磁盘,没有丢数据的风险,风险低,但是写入慢。
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。该策略主机掉电后会丢数据,但是MySQL异常重启不会丢数据,风险较低,写入比较快。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
这里和与binlog不同,binlog是每个线程都有一个binlog cache,而redo log是多个线程共用一个redo log buffer。
事务执行过程中的redo log也是直接写在redo log buffer中的,这些 redo log 也会被后台线程一起持久化到磁盘。
实际上,除了后台线程每秒一次的轮训操作,还有两种场景会让一个没有提交的事务redo log写入到磁盘中。
- redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时候,后台线程会主动写盘。注意,由于这个事务并没有提交,所以这个写盘动作只是 write,而没有调用 fsync,也就是只留在了文件系统的 page cache。
- 并行的事务提交的时候,顺带将这个事务的redo log buffer持久化到磁盘。假设一个事务A执行了一半,写了一半redo log 到 buffer 中,这时候有另外一个线程的事务 B 提交,如果 innodb_flush_log_at_trx_commit 设置的是 1,那么按照这个参数的逻辑,事务 B 要把 redo log buffer 里的日志全部持久化到磁盘。这时候就会带上事务A在redo log buffer里的日志一起持久化到磁盘。
两阶段提交:redo log先prepare,再写binlog,最后再把redo log commit。
# 组提交
这个概念有点类似WAL,就是积累一点数量后再提交,节约磁盘IOPS。
日志逻辑序列号(log sequence number,LSN):LSN是单调递增的,用来对应redo log的一个个写入点,每次写入长度为length的redo log, LSN的值就会加上length。
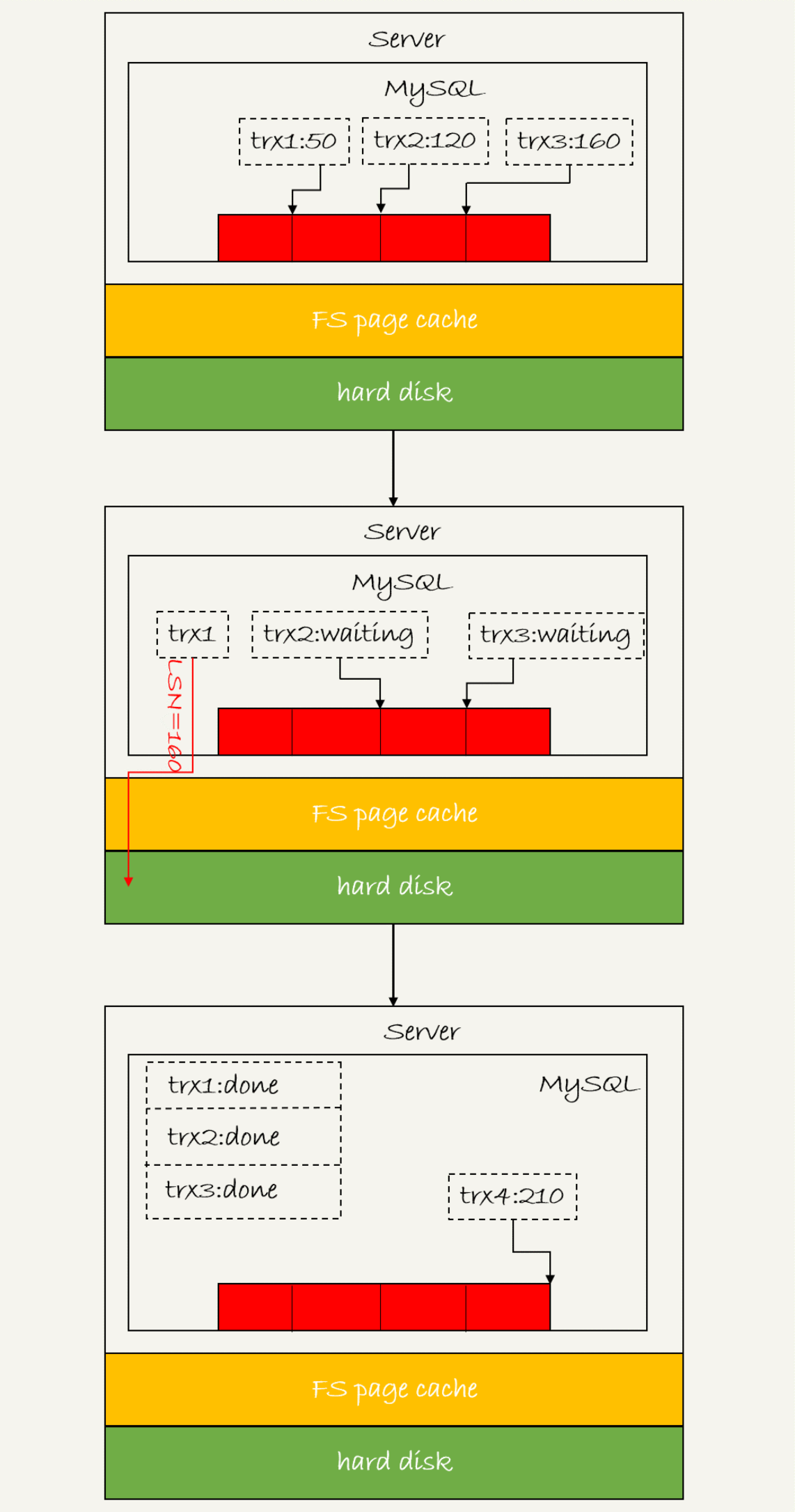
上图流程如下:
- trx1 是第一个到达的,会被选为这组的 leader;
- 等 trx1 要开始写盘的时候,这个组里面已经有了三个事务,这时候 LSN 也变成了 160;
- trx1 去写盘的时候,带的就是 LSN=160,因此等 trx1 返回时,所有 LSN 小于等于 160 的 redo log,都已经被持久化到磁盘;
- trx2和trx3就可以直接返回了。
一次组提交里面,组员越多,节约磁盘IOPS的效果越好。
在并发更新场景下,第一个事务写完 redo log buffer 以后,接下来这个 fsync 越晚调用,组员可能越多,节约 IOPS 的效果就越好。
那么MySQL是如何让一次fsync带的组员更多的呢?拖时间
两阶段提交的详细图如下:
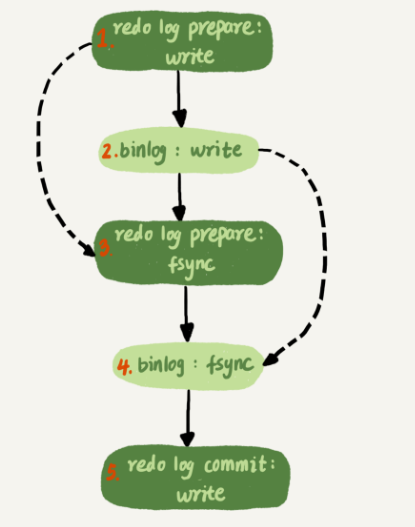
binlog的写是分成两步的:
- 先把 binlog 从 binlog cache 中写到磁盘上的 binlog 文件;
- 调用 fsync 持久化。
也就是说MySQL延长了写binlog这个过程,让组内的成员更多,在步骤4把binlog fsync到磁盘的时候,如果有多个事务的binlog已经写完了,也是一起持久化的,这样就可以减少IOPS的消耗。
WAL机制是减少磁盘写,它主要得益于:
- redo log 和 binlog 都是顺序写,磁盘的顺序写比随机写速度要快;
- 组提交机制,可以大幅度降低磁盘的 IOPS 消耗。