 MySQL深入36-insert语句的锁
MySQL深入36-insert语句的锁
# MySQL深入36-insert语句的锁
MySQL由于对并发度的考虑,对自增主键锁做了优化,尽量在申请到自增id以后,就释放自增锁。但是对于有些insert语句是属于“特殊情况”的,在执行过程中需要给其他资源加锁。
# insert...select语句
首先创建案例数据库:
CREATE TABLE `t` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(null, 1,1);
insert into t values(null, 2,2);
insert into t values(null, 3,3);
insert into t values(null, 4,4);
create table t2 like t
在可重复读隔离级别下,binlog_format=statement 时执行:

如果session B先执行,由于这个语句对表t主键索引加了(-∞,1]这个 next-key lock,所以session A的insert语句只能在session B执行完成后才能执行。
如果没有锁的情况,就可能出现session B的inset语句先执行,在 binlog_format=statement 的情况下,binlog 里面就记录了这样的语句序列:
insert into t values(-1,-1,-1);
insert into t2(c,d) select c,d from t;
这样的binlog拿到备库执行,就会把id=-1这一行数据也写入表t2中,出现主备不一致的情况。
# insert 循环写入
执行insert...select的时候,对目标表也不是锁全表,而是只锁住需要访问的资源。
insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
上述SQL语句相当于要往表 t2 中插入一行数据,这一行的 c 值是表 t 中 c 值的最大值加 1。
order by c desc定位最大值是一个范围查找,范围查询都需要访问到不满足条件的第一个值为止。因此最终加锁的范围为(3,4]和 (4,supremum]这两个 next-key lock,以及主键索引上 id=4 这一行。那么这条语句最终扫描的是一行。
如果是要把这一行数据循环插入到表t中:
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
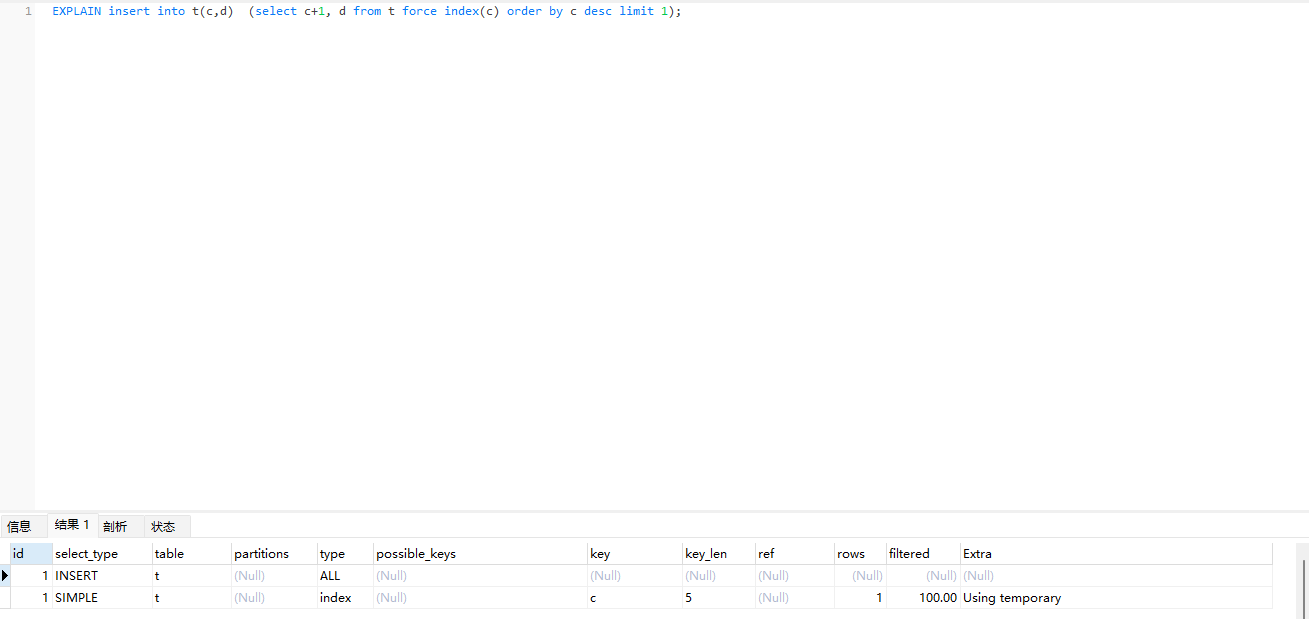
可以看到这条语句是使用了临时表的,我们来分析一下执行流程:
- 创建临时表,表里有两个字段 c 和 d。
- 按照索引 c 扫描表 t,依次取 c=4、3、2、1,然后回表,读到 c 和 d 的值写入临时表。这时,Rows_examined=4。
- 由于语义里面有 limit 1,所以只取了临时表的第一行,再插入到表 t 中。这时,Rows_examined 的值加 1,变成了 5。
# Time: 2022-07-04T01:52:51.170008Z
# User@Host: root[root] @ localhost [::1] Id: 17
# Query_time: 0.001225 Lock_time: 0.000091 Rows_sent: 0 Rows_examined: 5
SET timestamp=1656899571;
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
也就是说,这个语句会导致在表 t 上做全表扫描,并且会给索引 c 上的所有间隙都加上共享的 next-key lock。所以,这个语句执行期间,其他事务不能在这个表上插入数据。
为什么需要临时表
一边遍历数据,一边更新数据的情况,如果读出来的数据直接写回原表,就可能在遍历过程中,读到刚刚插入的记录,新插入的记录如果参与计算逻辑,就跟语义不符。
如何优化
使用内存临时表的方式,先把数据读出来插入内存临时表,然后在从临时表读出来插入表t1。
create temporary table temp_t(c int,d int) engine=memory;
insert into temp_t (select c+1, d from t force index(c) order by c desc limit 1);
insert into t select * from temp_t;
drop table temp_t;
# insert 唯一键冲突
对于有唯一键的表,插入数据时出现唯一键冲突也是常见的情况。

session A执行的inset语句,发生唯一键冲突的时候,并不只是简单地报错,还在冲突的索引上了加了锁。
session A 持有索引 c 上的 (5,10]共享 next-key lock(读锁),因此session B会被阻塞。
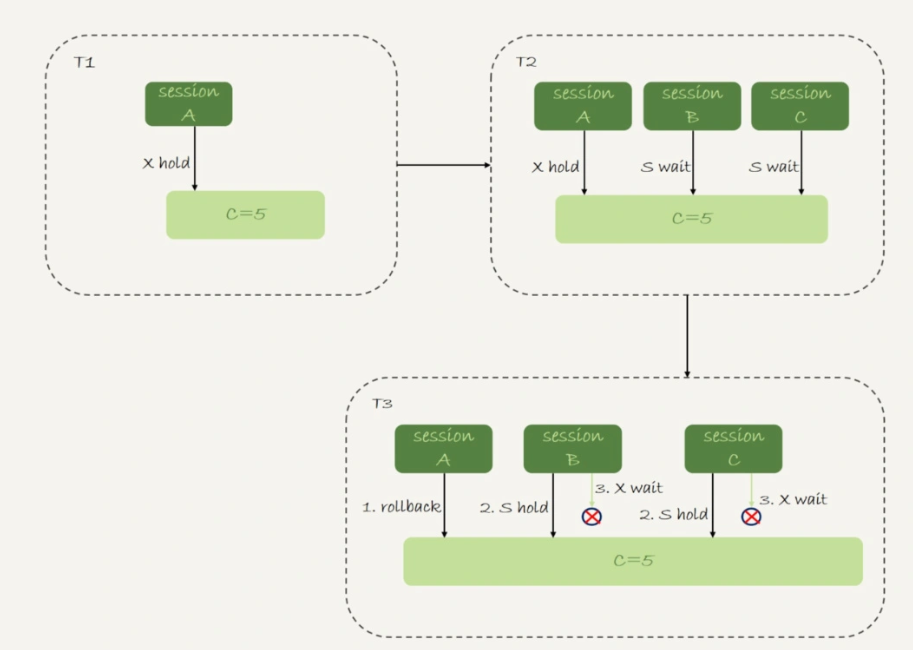
下面是一个唯一键冲突导致的死锁场景:

- 在 T1 时刻,启动 session A,并执行 insert 语句,此时在索引 c 的 c=5 上加了行锁。
- 在 T2 时刻,session B 要执行相同的 insert 语句,发现了唯一键冲突,加上读锁;同样地,session C 也在索引 c 上,c=5 这一个记录上,加了读锁。
- T3 时刻,session A 回滚。这时候,session B 和 session C 都试图继续执行插入操作,都要加上写锁。两个 session 都要等待对方的行锁,所以就出现了死锁。
# insert into ... on duplicate key update
insert into … on duplicate key update 这个语义的逻辑是,插入一行数据,如果碰到唯一键约束,就执行后面的更新语句。
注意,如果有多个列违反了唯一性约束,就会按照索引的顺序,修改跟第一个索引冲突的行。
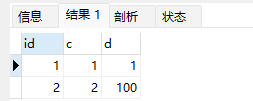
现在表t中里面已经有了 (1,1,1) 和 (2,2,2) 这两行,执行下面这条SQL语句:
insert into t values(2,1,100) on DUPLICATE key update d = 100;
可以看到,主键 id 是先判断的,MySQL 认为这个语句跟 id=2 这一行冲突,所以修改的是 id=2 的行。
# 小结
insert … select 是很常见的在两个表之间拷贝数据的方法。你需要注意,在可重复读隔离级别下,这个语句会给 select 的表里扫描到的记录和间隙加读锁。
而如果 insert 和 select 的对象是同一个表,则有可能会造成循环写入。这种情况下,我们需要引入用户临时表来做优化。
insert 语句如果出现唯一键冲突,会在冲突的唯一值上加共享的 next-key lock(S 锁)。因此,碰到由于唯一键约束导致报错后,要尽快提交或回滚事务,避免加锁时间过长。