MySQL深入16-查询一行数据执行慢
MySQL深入16-查询一行数据执行慢
# MySQL深入-查询一行数据执行慢
一些复杂语句我们会对其进行优化,但是有时候即使查询一行数据也会变得非常慢。
通过下面的语句:给一张简单表插入10w条数据
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=100000) do
insert into t values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
# 查询长时间不返回
# 等 MDL 锁
select * from t where id=1;
一般碰到这种情况的话,大概率就是表t被锁住了。我们来复现一下这个情况,然后再进行分析。

session A 通过 lock table 命令持有表 t 的 MDL 写锁,而 session B 的查询需要获取 MDL 读锁。所以,session B 进入等待状态。
我们可以执行show processlist命令,来查看当前语句处于什么状态

可以看到ID=70这条SQL语句state是Waiting for table metadata lock,出现这个状态表示:现在有一个线程正在表t上请求或者持有MDL写锁,把select语句堵住了。
这类问题的处理方式:就是找到谁持有MDL写锁,然后把它kill掉。
通过查询 sys.schema_table_lock_waits 这张表,我们就可以直接找出造成阻塞的 process id,把这个连接用 kill 命令断开即可。
# 等flush
首先还是来复现一下情况:

session A中相当于每一行休眠1秒,t中一共有10w行,所以要默认执行10万秒。

可以查看ID=77的SQL语句线程状态是waiting for table flush,这个状态表示:现在有一个线程要对表t做flush操作,一般有以下两个:
- flush tables t with read lock;
- flush tables with read lock;
如果指定表 t 的话,代表的是只关闭表 t;如果没有指定具体的表名,则表示关闭 MySQL 里所有打开的表。
id=78的SQL阻塞原因:有一个 flush tables 命令被别的语句堵住了,然后它又堵住了我们的 select 语句。
在这期间表 t 一直是被 session A“打开”着。然后,session B 的 flush tables t 命令再要去关闭表 t,就需要等 session A 的查询结束。这样,session C 要再次查询的话,就会被 flush 命令堵住了。
# 等行锁
select * from t where id=1 lock in share mode;
我们知道这条语句访问id=1这条记录会加读锁,如果这个时候已经有一个事务在这行记录上持有一个写锁,我们的select语句就会被堵住。

session A启动了事务,占据了id=1这条记录的写锁,然后也没有提交,导致session B被堵住。
可以通过以下命令查看到谁占着这个写锁:
select * from sys.innodb_lock_waits where locked_table='`test`.`t`'

这里通过kill 80,直接断开这个连接。断开连接的时候,会自动回滚这个连接里面正在执行的线程·,也就释放了id=1上的行锁。
# 查询慢
select * from h where c=50000 limit 1;
由于字段c上没有索引,所以这条语句只能一条一条遍历,因此需要扫描5W行。
# Time: 2022-06-17T06:15:31.105116Z
# User@Host: root[root] @ localhost [::1] Id: 84
# Query_time: 0.006709 Lock_time: 0.000189 Rows_sent: 1 Rows_examined: 50000
SET timestamp=1655446531;
select * from h where c=50000 limit 1;
下面看一个只扫描一行的查询语句:
select * from t where id=1;
# Time: 2022-06-17T06:21:40.038710Z
# User@Host: root[root] @ localhost [::1] Id: 84
# Query_time: 0.000141 Lock_time: 0.000065 Rows_sent: 1 Rows_examined: 1
SET timestamp=1655446900;
select * from h where id=1;
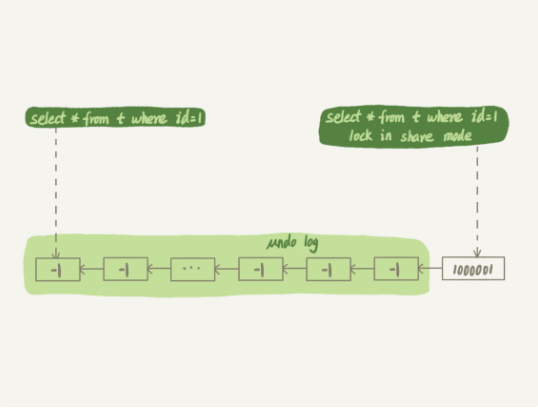
下面我们试想一个场景,如果事务A在查询之前,事务B让某一行数据增加了100W次,
那么在事务A拿到数据的时候是最新的数据,但是这个数据不属于它,就会使用undo log往前面找,把属于自己的结果返回。

session B 更新完 100 万次,生成了 100 万个回滚日志 (undo log)。
带 lock in share mode 的 SQL 语句,是当前读,因此会直接读到 1000001 这个结果,所以速度很快;而 select * from t where id=1 这个语句,是一致性读,因此需要从 1000001 开始,依次执行 undo log,执行了 100 万次以后,才将 1 这个结果返回。