MySQL深入13-order by
MySQL深入13-order by
# MySQL深入-order by
某些业务会要求按照某一个字段来排序显示结果,这个时候我们往往会使用order by来进行排序。比如我们去查询一张市民表,要求返回按照姓名排序前1000个人的姓名、年龄,且这些人的城市为杭州。
select city,name,age from t where city='杭州' order by name limit 1000 ;
# 全字段排序
为了避免全表扫描,我们需要在city字段上加上索引,下面通过explain命令来查看这个语句执行的情况:
EXPLAIN select city,name,age from t where city='杭州' order by name limit 1000 ;

Extra这个字段中的using filesort表示的就是需要排序,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
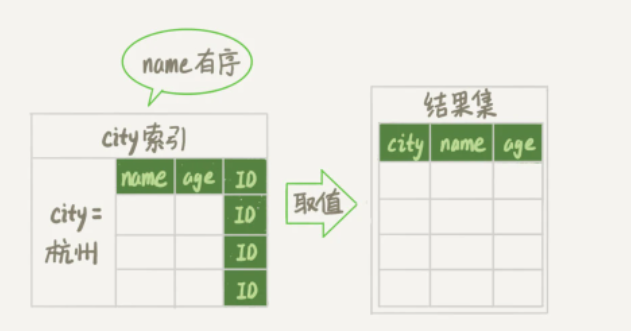
通过上图,我们来对该SQL语句的执行过程进行分析:
初始化 sort_buffer,确定放入 name、city、age 这三个字段;
再从city索引树上进行查找,查找到第一个city=杭州的数据,获取它的主键ID_X。
通过ID_X去主键索引树上取到整行数据,然后从整行数据从取出name、city、age三个字段的数值,存入sort_buffer中。
从city索引树中查找下一个满足条件的数据。
重复步骤3和4直到city的值不满足查询条件。
对sort_buffer中的数据按照字段name进行排序。
把排序结果的前1000个返回给客户端。
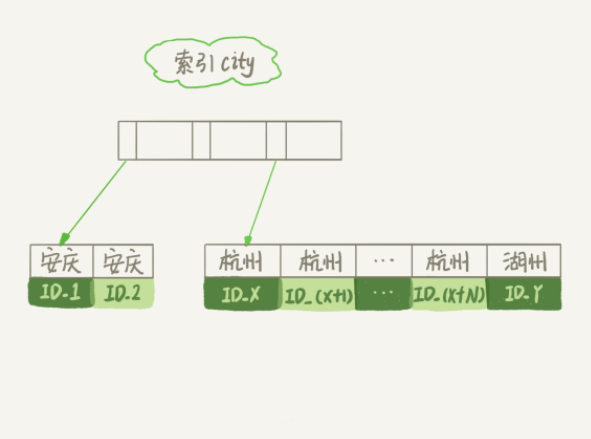
上诉过程执行的示意图如下:
图中按照name排序这个过程,是可能在内存中进行排序,也可能需要使用外部排序,这取决排序所需的内存和参数sort_buffer_size。
sort_buffer_size:就是MySQL给sort_buffer开辟的内存大小,如果要排序的数据量小于sort_buffer_size,那么排序就在内存中进行,反之就需要利用磁盘临时文件去复制排序。
临时文件数(number_of_tmp_files):当使用外部排序的时候,就会用到临时文件。 临时文件可以理解为MySQL把要排序的数据分成N份,每份单独排序后存在这些临时文件中,然后把这N份有序文件再合并成一个有序的大文件。
# rowid排序
全字段排序中会分配一个排序的缓冲区,然后会根据待排序的数据量和sort_buffer_size来决定进行内存排序还是外部排序。
但是如果我们查询的字段很多的话,那么sort_buffer里面一行数据就会有很多字段,导致内存同时放下的数据行很少,要分成很多个临时文件,排序的性能会很差。因此如果当行数据量很大的时候,使用全字段排序效率就不太好。
SET max_length_for_sort_data = 16;
max_length_for_sort_data: 是MySQL中专门控制用于排序的行数据长度的参数。如果单行数据的长度超过这个数值,MySQL就会换一种排序算法。
执行器查看表定义,发现name、city、age字段的长度之和超过max_length_for_sort_data,所以初始化sort_buffer的时候只放入id和name字段。
执行流程如下:
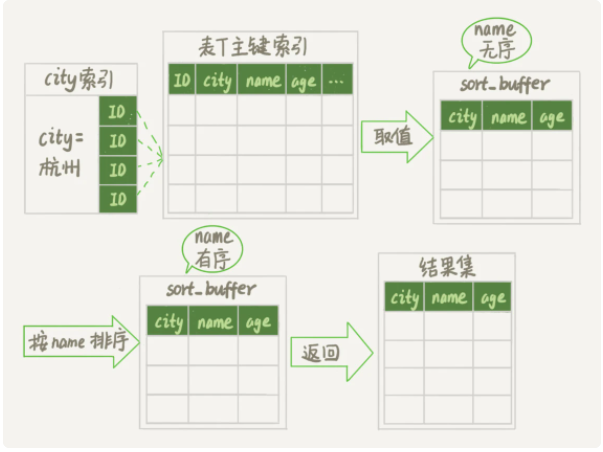
- 初始化sort_buffer,确定放入两个字段,name和id;
- 再从city索引树上进行查找,查找到第一个city=杭州的数据,获取它的主键ID_X。
- 通过ID_X去主键索引树上取到整行数据,然后从整行数据从取出name、id两个字段的数值,存入sort_buffer中。
- 从city索引树查找下一个满足条件的数值。
- 重复步骤3和4直到city的值不满足查询条件。
- 对sort_buffer中的数据按照字段name进行排序。
- 遍历排序结果,取前 1000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
上诉执行流程的示意图如下:
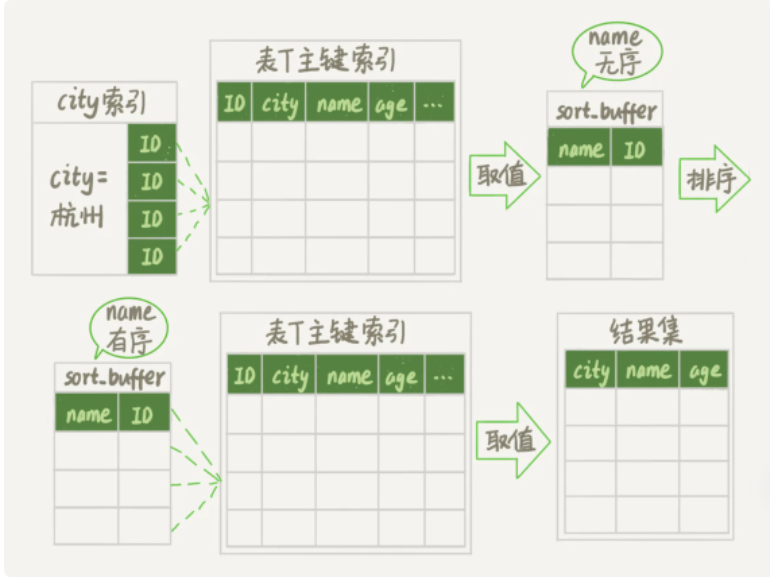
可以看到rowid排序和全字段排序最大的区别就是它多去访问了一次主键索引树。
需要说明的是,最后的“结果集”是一个逻辑概念,实际上 MySQL 服务端从排序后的 sort_buffer 中依次取出 id,然后到原表查到 city、name 和 age 这三个字段的结果,不需要在服务端再耗费内存存储结果,是直接返回给客户端的。
# 两种排序的区别
MySQL如果认为内存大,会优先选择全字段排序,把需要的字段放到sort_buffer中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。
其实两者最终的选择是考虑到内存,内存的考虑是sort_buffer放入的字段,字段太多就会导致单行数据量过大,单行数据量大,意味着内存就放不下那么多数据。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
由于rowId排序会回表造成磁盘读,因此不会被优先选择。
经过上面的分析,可以看到order by是一个成本比较高的操作。但是并非所有的order by操作都需要排序的,之所以需要进行排序是原来的数据是无序的。如果我们可以通过某种方式让需要排序字段本身就是有序的呢?
在上述案例中,我们可以让name字段本身就是递增排序的,通过创建一个city和name的联合索引:
alter table t add index city_user(city, name);
现在我们来分析一下在这个联合索引下查询语句的执行过程:
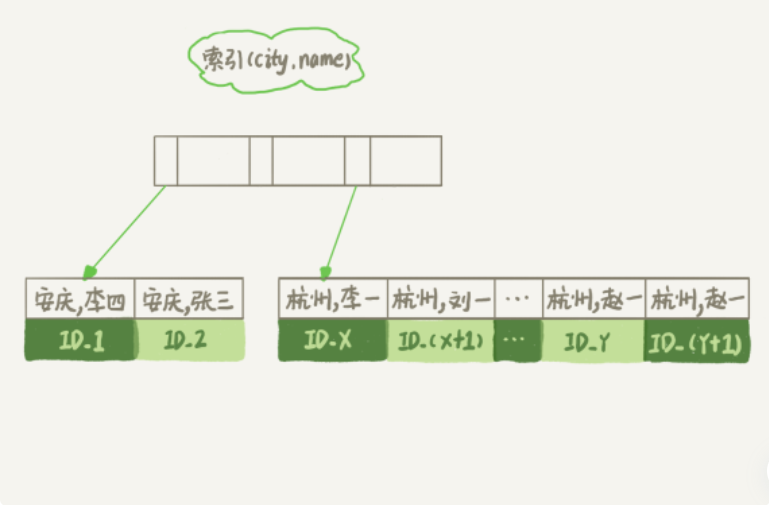
- 从索引(city,name)找到第一个满足条件的主键id
- 从主键索引中取出整行数据,去name、city、age三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name) 取下一个记录主键 id;
- 重复步骤 2、3,直到查到第 1000 条记录,或者是不满足 city='杭州’条件时循环结束。
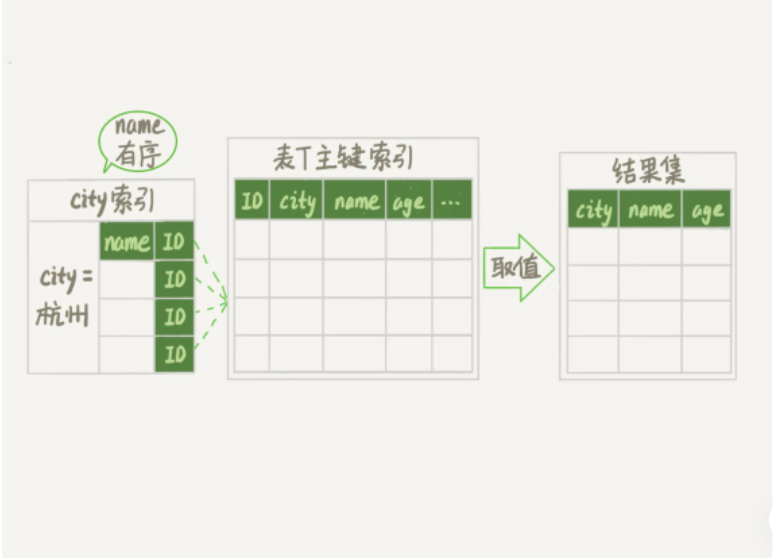
可以看到这个查询过程中是不需要临时表、也不需要排序的,我们使用explain命令进行验证。

从图中可以看到,Extra 字段中没有 Using filesort 了,也就是不需要排序了。而且由于 (city,name) 这个联合索引本身有序,所以只需要找到满足条件的前1000条记录就可以退出了。
进一步优化
由于我们只需要name、age所以我们可以使用覆盖索引的方式来进一步优化这个查询语句,减少回表的次数。
覆盖索引是指,索引上的信息足够满足查询请求,不需要再回到主键索引上去取数据。
alter table t add index city_user_age(city, name, age);
执行流程如下:
- 从索引 (city,name,age) 找到第一个满足 city='杭州’条件的记录,取出其中的 city、name 和 age 这三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name,age) 取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
- 重复执行步骤 2,直到查到第 1000 条记录,或者是不满足 city='杭州’条件时循环结束。