 MySQL深入34-InnoDB和Memory
MySQL深入34-InnoDB和Memory
# MySQL深入34-InnoDB和Memory
首先我们就内存表的数据组织结构进行分析,假设有以下的两张表 t1 和 t2,其中表 t1 使用 Memory 引擎, 表 t2 使用 InnoDB 引擎。
create table t1(id int primary key, c int) engine=Memory;
create table t2(id int primary key, c int) engine=innodb;
insert into t1 values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
insert into t2 values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6),(7,7),(8,8),(9,9),(0,0);
然后分别对两表进行全表查询,发现结果不一致:
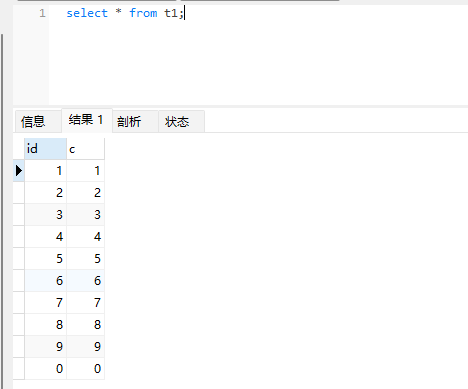
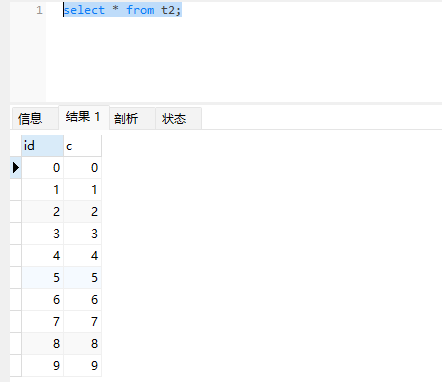
可以看到,t1的返回结果里面0在最后一行,而表t2的返回结果里面0在第一行。出现这个原因在于两个引擎的主键索引的组织方式不同。
表t2使用的是InnoDB引擎,主键索引是B+树,数据组织方式如下:
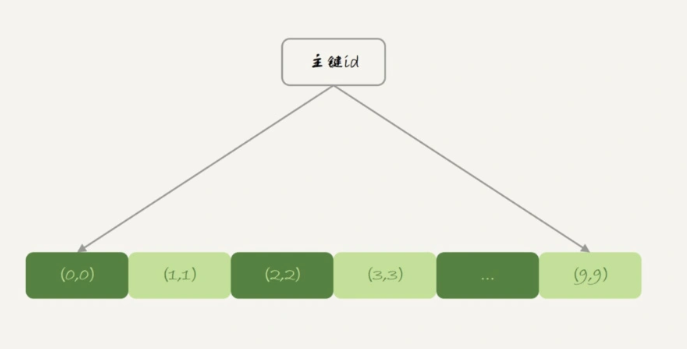
由于主键索引上的值是有序存储的,在执行select * 的时候,就会按照叶子节点从左到右扫描,所以得到的结果里,0 就出现在第一行。
而Memory引擎的数据和索引是分开存储的:
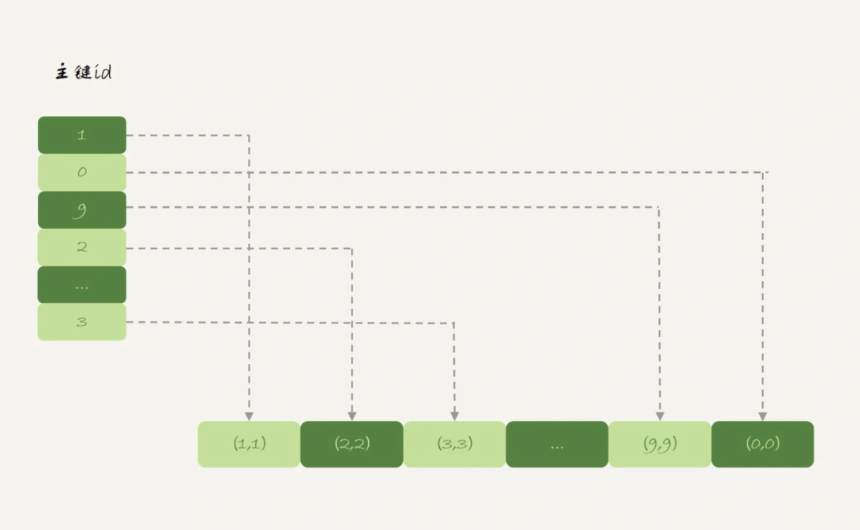
内存表的数据部分是以数组的方式单独存放的,而主键id索引里,存的是每个数据的位置。主键id是hash索引,可以看到索引上的key并不是有序的。
因此当执行select *的时候,就是顺序扫描这个数组,因此,0就是最后一个被读到的。
InnoDB和Memory引擎的数据组织方式是不同的:
- InnoDB 引擎把数据放在主键索引上,其他索引上保存的是主键 id。这种方式,我们称之为索引组织表(Index Organizied Table)。
- 而 Memory 引擎采用的是把数据单独存放,索引上保存数据位置的数据组织形式,我们称之为堆组织表(Heap Organizied Table)。
两者引擎的区别:
- InnoDB 表的数据总是有序存放的,而内存表的数据就是按照写入顺序存放的;
- 当数据文件有空洞的时候,InnoDB 表在插入新数据的时候,为了保证数据有序性,只能在固定的位置写入新值,而内存表找到空位就可以插入新值;
- 数据位置发生变化的时候,InnoDB 表只需要修改主键索引,而内存表需要修改所有索引;
- InnoDB 表用主键索引查询时需要走一次索引查找,用普通索引查询的时候,需要走两次索引查找(回表)。而内存表没有这个区别,所有索引的“地位”都是相同的。
- InnoDB 支持变长数据类型,不同记录的长度可能不同;内存表不支持 Blob 和 Text 字段,并且即使定义了 varchar(N),实际也当作 char(N),也就是固定长度字符串来存储,因此内存表的每行数据长度相同。
# Hash 索引和B-Tree 索引
实际上,内存表也是支持B-Tree索引的。在id列上创建一个B-Tree索引:
alter table t1 add index a_btree_index using btree (id);
经过上述语句之后,表t1的数据组织形式为:
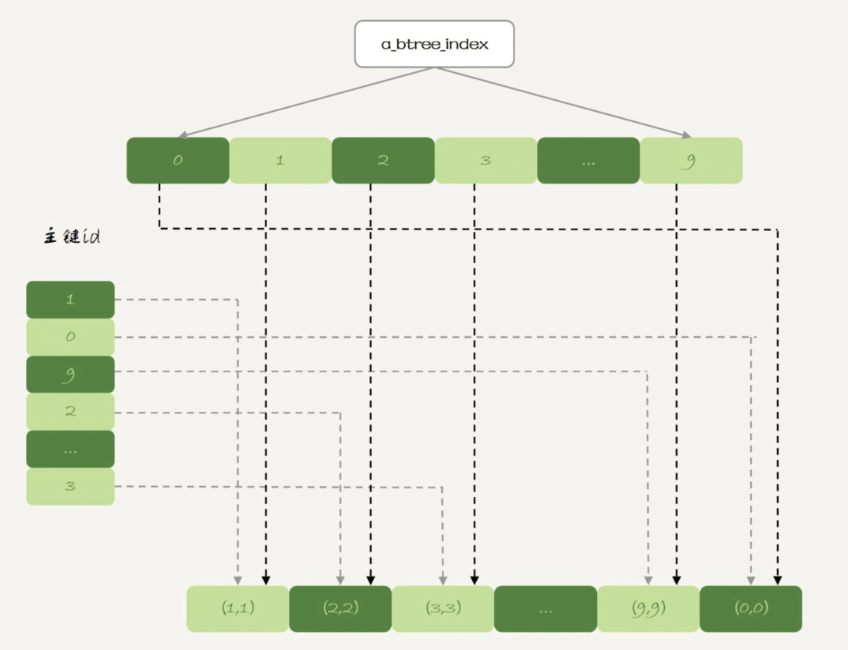
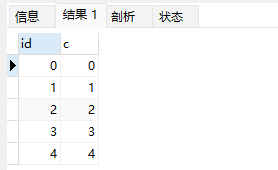
select * from t1 where id < 5;
select * from t1 force index(primary) where id < 5;
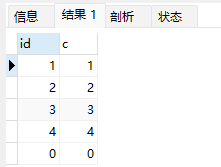
可以看到,执行 select * from t1 where id<5 的时候,优化器会选择 B-Tree 索引,所以返回结果是 0 到 4。 使用 force index 强行使用主键 id 这个索引,id=0 这一行就在结果集的最末尾了。
接下来讨论一下内存表的几个缺点。
# 内存表的锁
内存表不支持行锁,只支持表锁。因此,一张表只要有更新,就会堵住其他所有在这个表上的读写操作。
跟行锁比起来,表锁对并发访问的支持不够好。所以,内存表的锁粒度问题,决定了它在处理并发事务的时候,性能也不会太好。
# 数据持久性问题
数据放在内存中,存的读写速度总是比磁盘快,这是内存表的优势,但也是一个劣势。因为,数据库重启的时候,所有的内存表都会被清空。在高可用架构下,内存表这个特点反而成了bug。
M-S架构
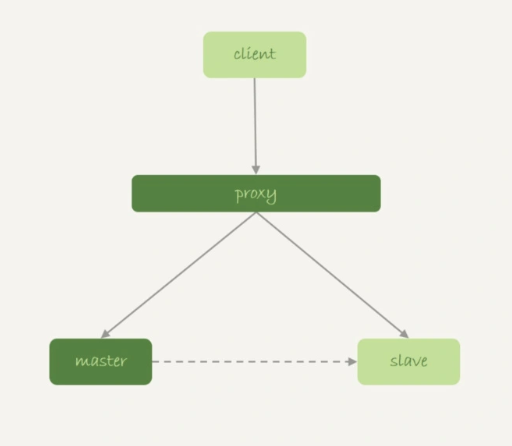
- 业务正常访问主库;
- 备库硬件升级,备库重启,内存表t1内容被清空;
- 备库重启后,客户端发送一条update语句,修改表t1的数据行,这时备库应用线程就会报错“找不到要更新的行”。
这样就会导致主备同步停止了,如果这时候发生主备切换的话,客户端会看到,表t1的数据“丢失”了。由于MySQL知道重启之后,内存表的数据会丢失。所以,担心主库重启之后,出现主备不一致,MySQL往 binlog 里面写入一行 DELETE FROM t1。
如果使用的是双M结构的话,在备库重启的时候,备库binlog里面的delete语句就会被传到主库,然后把主库内存表的内容删除。