 MySQL深入39-分区表
MySQL深入39-分区表
# MySQL深入39-分区表
为了对分区表的组织形式进行了解,我们先创建一个表t:
CREATE TABLE `t` (
`ftime` datetime NOT NULL,
`c` int(11) DEFAULT NULL,
KEY (`ftime`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY RANGE (YEAR(ftime))
(PARTITION p_2017 VALUES LESS THAN (2017) ENGINE = InnoDB,
PARTITION p_2018 VALUES LESS THAN (2018) ENGINE = InnoDB,
PARTITION p_2019 VALUES LESS THAN (2019) ENGINE = InnoDB,
PARTITION p_others VALUES LESS THAN MAXVALUE ENGINE = InnoDB);
insert into t values('2017-4-1',1),('2018-4-1',1);
在表t中初始化插入了两条记录,按照定义的分区规则,这两行记录分别落在 p_2018 和 p_2019 这两个分区上。
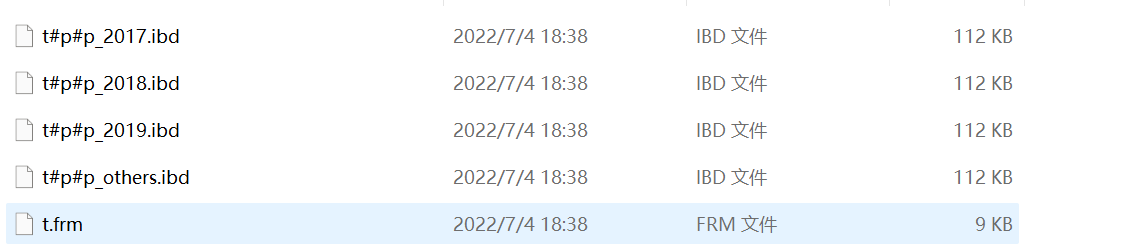
可以看到,这个表包含了一个.frm 文件和 4 个.ibd 文件,每个分区对应一个.ibd 文件。也就是说:
- 对于引擎层来说,这是 4 个表;
- 对于 Server 层来说,这是 1 个表。
# 分区表的引擎层行为
上面我们分析过,这个表对于引擎层来说,这是 4 个表,这是为什么呢?
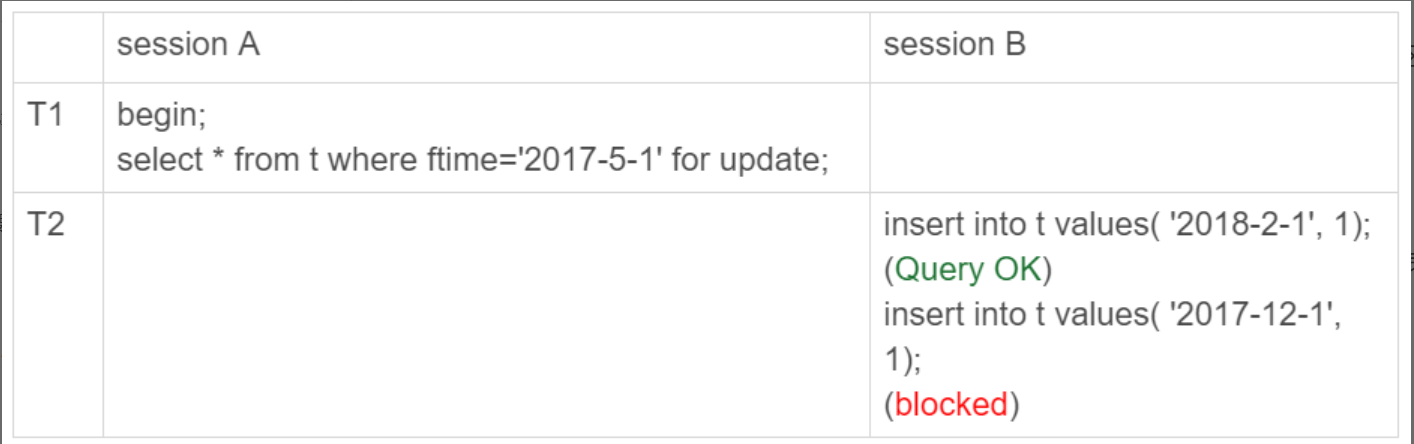
现在假设这个表对于引擎层而言是一个表,那么由于session A的 select 语句对索引 ftime 上这两个记录之间的间隙加了锁。那么在T1时刻,对表t的ftime索引上,加锁状态如下: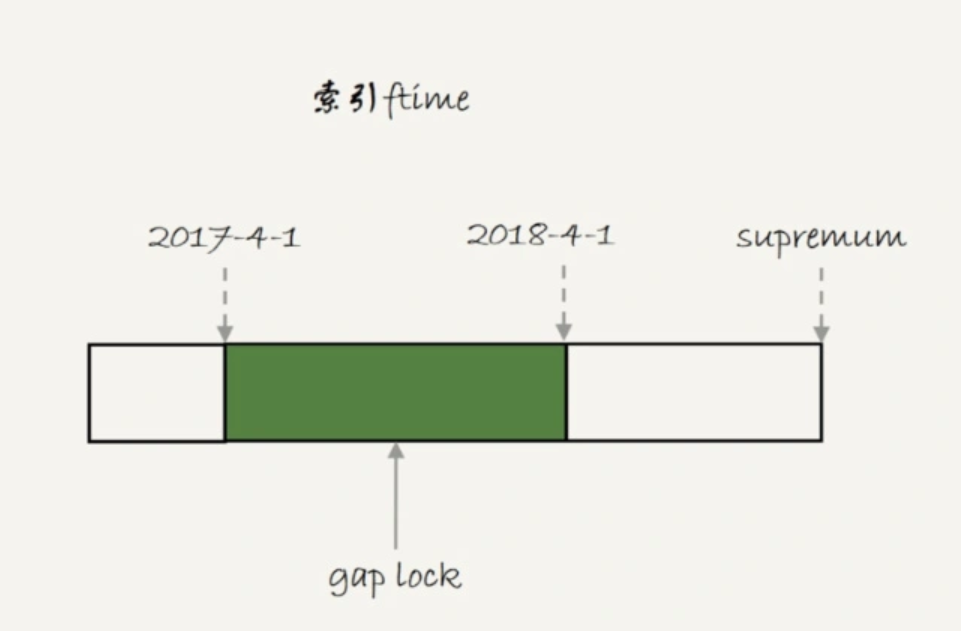
也就是说,'2017-4-1' 和'2018-4-1' 这两个记录之间的间隙是会被锁住的。那么,sesion B 的两条插入语句应该都要进入锁等待状态。
那么对于session B而言两条插入语句应该都要进入锁等待状态。但是第一条插入语句却能够成功执行,这是因为p_2018 和 p_2019 是两个不同的表,也就是说 2017-4-1 的下一个记录并不是 2018-4-1,而是 p_2018 分区的 supremum。所以 T1 时刻,在表 t 的 ftime 索引上,间隙和加锁的状态其实是图 4 这样的:
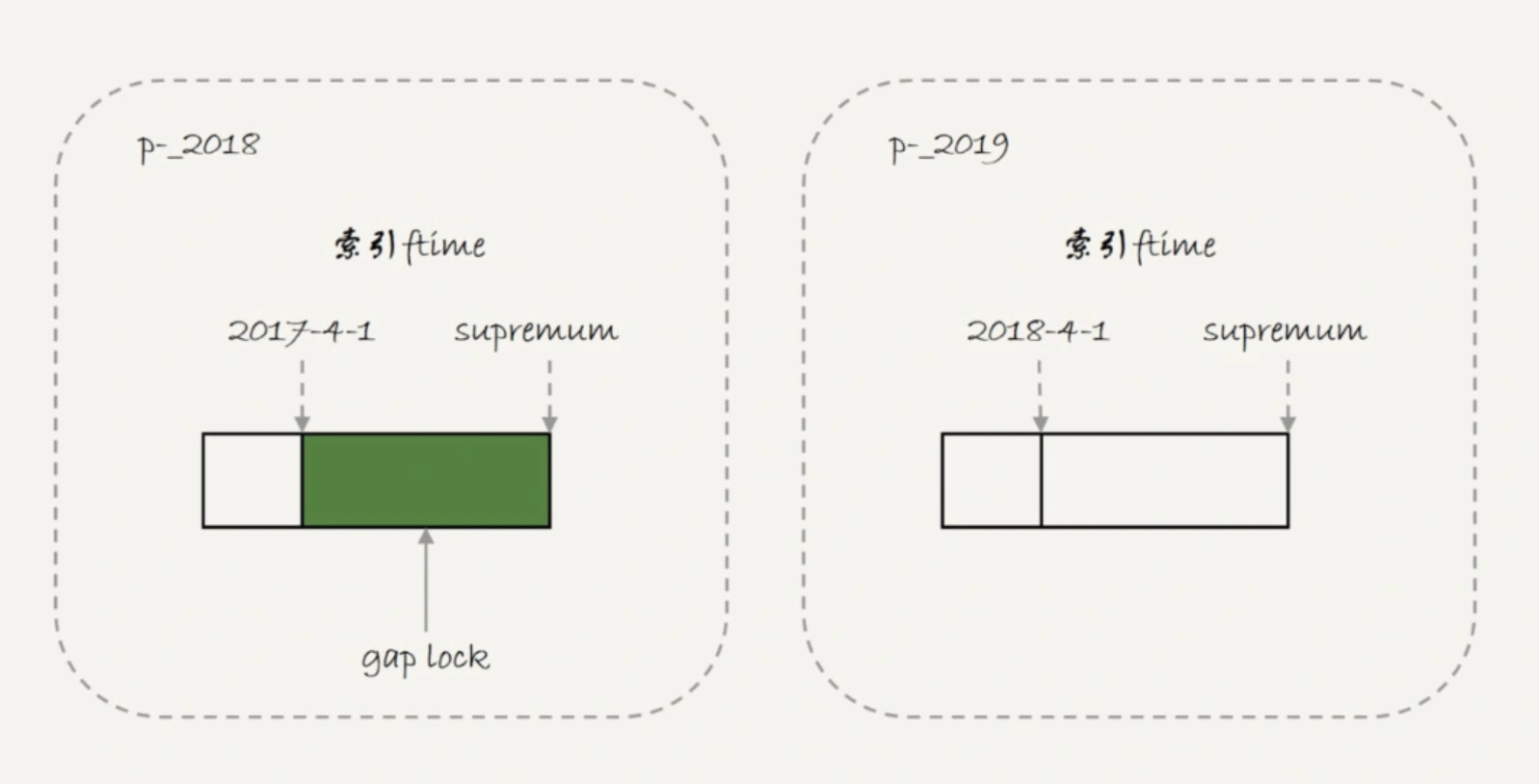
由于分区的规则,相当于session A的语句其实只操作了分区p_2018,因此加锁范围就是图中深绿色的部分。所以session B 要写入一行 ftime 是 2018-2-1 的时候是可以成功的,而要写入 2017-12-1 这个记录,就要等 session A 的间隙锁。
# 分区表的server层行为
对于server层来说,一个分区表就只是一个表。
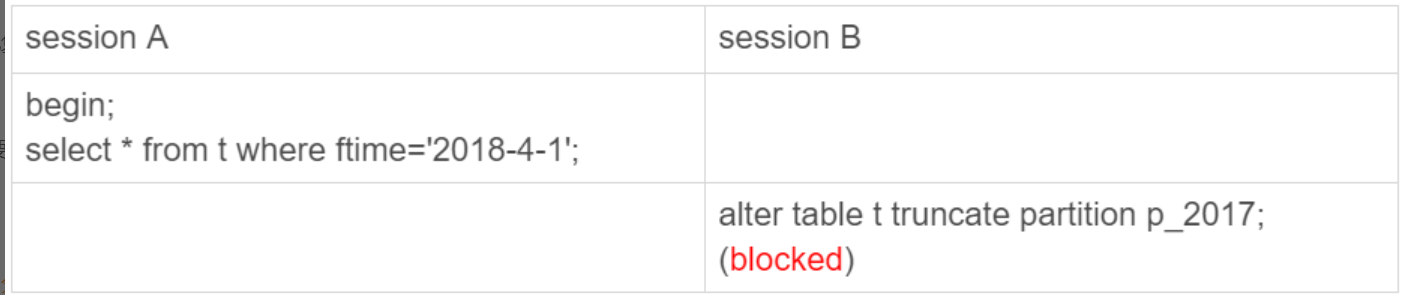
可以看到,虽然 session B 只需要操作 p_2017 这个分区,但是由于 session A 持有整个表 t 的 MDL 锁,就导致了 session B 的 alter 语句被堵住。
通过分区表在server层和引擎层的行为案例的分析,我们小结如下:
- MySQL 在第一次打开分区表的时候,需要访问所有的分区;
- 在 server 层,认为这是同一张表,因此所有分区共用同一个 MDL 锁;
- 在引擎层,认为这是不同的表,因此 MDL 锁之后的执行过程,会根据分区表规则,只访问必要的分区。
# 分区表的应用场景
分区表的一个显而易见的优势是对业务透明,相对于用户分表来说,使用分区表的业务代码更简洁。还有,分区表可以很方便的清理历史数据。
如果一项业务跑的时间足够长,往往就会有根据时间删除历史数据的需求。这时候,按照时间分区的分区表,就可以直接通过 alter table t drop partition ... 这个语法删掉分区,从而删掉过期的历史数据。