 Redis核心技术11-时间序列数据存储
Redis核心技术11-时间序列数据存储
# Redis核心技术11-时间序列数据存储
场景1:记录用户在网站或者 App 上的点击行为数据,来分析用户行为。这里的数据一般包括用户 ID、行为类型(例如浏览、登录、下单等)、行为发生的时间戳
UserID, Type, TimeStamp
场景2:周期性地统计近万台设备的实时状态,包括设备 ID、压力、温度、湿度,以及对应的时间戳
DeviceID, Pressure, Temperature, Humidity, TimeStamp
这些与发生时间相关的一组数据,就是时间序列数据。这些数据的特点是没有严格的关系模型,记录的信息可以表示成键和值的关系。
# 时间序列数据的读写特点
时间序列数据通常是持续高并发写入的,并且写入主要就是插入新数据,也不会去更新一个已有的数据。所以,这种数据的写入特点很简单,就是插入数据快,这就要求我们选择的数据类型,在进行数据插入时,复杂度要低,尽量不要阻塞。
时间序列数据的读一般就会存在范围查询,比如某个时间段状态信息,有时候还会进行部分统计,比如对某个时间范围内的数据做聚合计算。这里的聚合计算,就是对符合查询条件的所有数据做计算,包括计算均值、最大 / 最小值、求和等
通过上述的分析,时间序列数据读写主要特点为:
- 写:写入数据要快。
- 读:支持单点查询、范围查询和聚合计算。
Redis 提供了保存时间序列数据的两种方案,分别可以基于 Hash 和 Sorted Set 实现,以及基于 RedisTimeSeries 模块实现。
# 基于 Hash 和 Sorted Set 保存时间序列数据
首先使用Hash和Sorted Set组合的方式有一个明显的好处:它们是 Redis 内在的数据类型,代码成熟和性能稳定。但是这边需要解决一个问题:为什么存储时间序列数据,我们要同时使用两种数据类型。
对于Hash,它的特点是:可以实现对单键的快速查询。这就满足了时间序列数据的单键查询需求。我们可以把时间戳作为 Hash 集合的 key,把记录的设备状态值作为 Hash 集合的 value。

当我们想要查询某个时间点或者是多个时间点上的温度数据时,直接使用 HGET 命令或者 HMGET 命令,就可以分别获得 Hash 集合中的一个 key 和多个 key 的 value 值了。
HGET device:temperature 202008030905
"25.1"
HMGET device:temperature 202008030905 202008030907 202008030908
1) "25.1"
2) "25.9"
3) "24.9"
但是Hash由于是无序的,所以不支持数据的范围查询,所以需要用 Sorted Set 来保存时间序列数据,因为它能够根据元素的权重分数来排序。我们可以把时间戳作为 Sorted Set 集合的元素分数,把时间点上记录的数据作为元素本身。
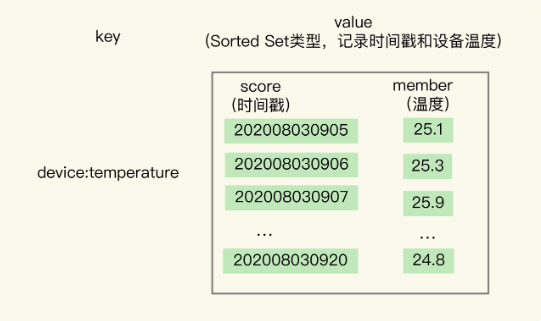
使用 Sorted Set 保存数据后,我们就可以使用 ZRANGEBYSCORE 命令,按照输入的最大时间戳和最小时间戳来查询这个时间范围内的温度值了。
ZRANGEBYSCORE device:temperature 202008030907 202008030910
1) "25.9"
2) "24.9"
3) "25.3"
4) "25.2"
为了满足时间序列的单点查询和范围查询,所以我们需要同时使用Hash和Sorted Set,现在又存在一个问题:如何保证写入 Hash 和 Sorted Set 是一个原子性的操作。
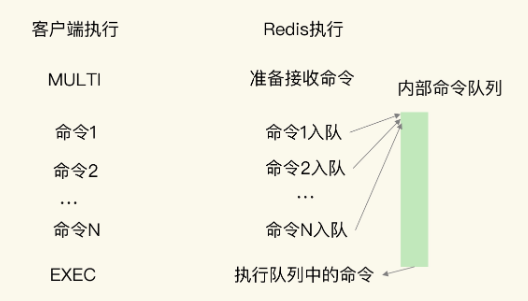
通过Redis自带的MULTI 和 EXEC 命令来实现简单的事务:
MULTI 命令:表示一系列原子性操作的开始。收到这个命令后,Redis 就知道,接下来再收到的命令需要放到一个内部队列中,后续一起执行,保证原子性。
EXEC 命令:表示一系列原子性操作的结束。一旦 Redis 收到了这个命令,就表示所有要保证原子性的命令操作都已经发送完成了。此时,Redis 开始执行刚才放到内部队列中的所有命令操作。
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> HSET device:temperature 202008030911 26.8
QUEUED
127.0.0.1:6379> ZADD device:temperature 202008030911 26.8
QUEUED
127.0.0.1:6379> EXEC
1) (integer) 1
2) (integer) 1
到这里,我们就解决了时间序列数据的单点查询、范围查询问题,并使用 MUTLI 和 EXEC 命令保证了 Redis 能原子性地把数据保存到 Hash 和 Sorted Set 中。接下来,我们需要继续解决第三个问题:如何对时间序列数据进行聚合计算?
因为 Sorted Set 只支持范围查询,无法直接进行聚合计算,所以,我们只能先把时间范围内的数据取回到客户端,然后在客户端自行完成聚合计算。这个方法虽然能完成聚合计算,但是会带来一定的潜在风险,也就是大量数据在 Redis 实例和客户端间频繁传输,这会和其他操作命令竞争网络资源,导致其他操作变慢。
如果只需要进行单个时间点查询或者是对某个时间范围查询的话,适合使用 Hash 和 Sorted Set 的组合,它们都是 Redis 的内在数据结构,性能好,稳定性高。但是,如果我们需要进行大量的聚合计算,同时网络带宽条件不是太好时,Hash 和 Sorted Set 的组合就不太适合了。此时,使用 RedisTimeSeries 就更加合适一些。
# 基于 RedisTimeSeries 模块保存时间序列数据
RedisTimeSeries 是 Redis 的一个扩展模块。它专门面向时间序列数据提供了数据类型和访问接口,并且支持在 Redis 实例上直接对数据进行按时间范围的聚合计算。
当用于时间序列数据存取时,RedisTimeSeries 的操作主要有 5 个:
- 用 TS.CREATE 命令创建时间序列数据集合;
- 用 TS.ADD 命令插入数据;
- 用 TS.GET 命令读取最新数据;
- 用 TS.MGET 命令按标签过滤查询数据集合;
- 用 TS.RANGE 支持聚合计算的范围查询。
# 用TS.CREATE创建一个时间序列数据集合
在 TS.CREATE 命令中,我们需要设置时间序列数据集合的 key 和数据的过期时间(以毫秒为单位)。此外,我们还可以为数据集合设置标签,来表示数据集合的属性。
TS.CREATE device:temperature RETENTION 600000 LABELS device_id 1
OK
上诉命令我们创建了一个 key 为 device:temperature、数据有效期为 600s 的时间序列数据集合。同时为这个集合设置了一个标签属性{device_id:1},表明这个数据集合中记录的是属于设备 ID 号为 1 的数据。
# 用 TS.ADD 命令插入数据,用 TS.GET 命令读取最新数据
我们可以用 TS.ADD 命令往时间序列集合中插入数据,包括时间戳和具体的数值,并使用 TS.GET 命令读取数据集合中的最新一条数据。
TS.ADD device:temperature 1596416700 25.1
1596416700
TS.GET device:temperature
25.1
# 用 TS.MGET 命令按标签过滤查询数据集合
在保存多个设备的时间序列数据时,我们通常会把不同设备的数据保存到不同集合中。此时,我们就可以使用 TS.MGET 命令,按照标签查询部分集合中的最新数据。在使用 TS.CREATE 创建数据集合时,我们可以给集合设置标签属性。当我们进行查询时,就可以在查询条件中对集合标签属性进行匹配,最后的查询结果里只返回匹配上的集合中的最新数据。
TS.MGET FILTER device_id!=2
1) 1) "device:temperature:1"
2) (empty list or set)
3) 1) (integer) 1596417000
2) "25.3"
2) 1) "device:temperature:3"
2) (empty list or set)
3) 1) (integer) 1596417000
2) "29.5"
3) 1) "device:temperature:4"
2) (empty list or set)
3) 1) (integer) 1596417000
2) "30.1"
上诉命令相当于查询device_id 不等于 2 的所有其他设备的数据集合,并返回各自集合中的最新的一条数据。
# 用 TS.RANGE 支持需要聚合计算的范围查询
在对时间序列数据进行聚合计算时,我们可以使用 TS.RANGE 命令指定要查询的数据的时间范围,同时用 AGGREGATION 参数指定要执行的聚合计算类型。RedisTimeSeries 支持的聚合计算类型很丰富,包括求均值(avg)、求最大 / 最小值(max/min),求和(sum)等。
TS.RANGE device:temperature 1596416700 1596417120 AGGREGATION avg 180000
1) 1) (integer) 1596416700
2) "25.6"
2) 1) (integer) 1596416880
2) "25.8"
3) 1) (integer) 1596417060
2) "26.1"
# 两种方案对比
第一种方案是,组合使用 Redis 内置的 Hash 和 Sorted Set 类型,把数据同时保存在 Hash 集合和 Sorted Set 集合中。这种方案既可以利用 Hash 类型实现对单键的快速查询,还能利用 Sorted Set 实现对范围查询的高效支持,一下子满足了时间序列数据的两大查询需求。但是在执行聚合计算时,我们需要把数据读取到客户端再进行聚合,当有大量数据要聚合时,数据传输开销大;另一个是,所有的数据会在两个数据类型中各保存一份,内存开销不小。不过,我们可以通过设置适当的数据过期时间,释放内存,减小内存压力。
RedisTimeSeries 模块。这是专门为存取时间序列数据而设计的扩展模块。和第一种方案相比,RedisTimeSeries 能支持直接在 Redis 实例上进行多种数据聚合计算,避免了大量数据在实例和客户端间传输。不过,RedisTimeSeries 的底层数据结构使用了链表,它的范围查询的复杂度是 O(N) 级别的,同时,它的 TS.GET 查询只能返回最新的数据,没有办法像第一种方案的 Hash 类型一样,可以返回任一时间点的数据。