 Redis核心技术14-CPU结构对Redis性能影响
Redis核心技术14-CPU结构对Redis性能影响
# Redis核心技术14-CPU结构对Redis性能影响
# 多核CPU架构
一个 CPU 处理器中一般有多个运行核心,我们把一个运行核心称为一个物理核,每个物理核都可以运行应用程序。每个物理核都拥有私有的一级缓存(Level 1 cache,简称 L1 cache),包括一级指令缓存和一级数据缓存,以及私有的二级缓存(Level 2 cache,简称 L2 cache)。
物理核的私有缓存是指缓存空间只能被当前这个物理核使用,其他的物理核无法对这个核的缓存空间进行数据存取。
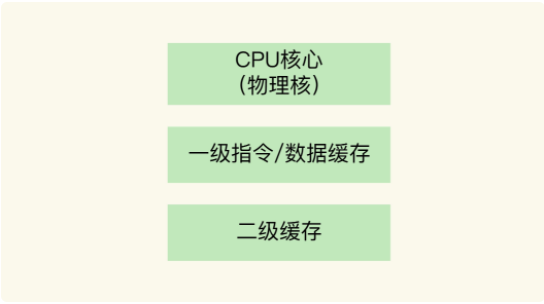
因为L1 和 L2 缓存是每个物理核私有的,所以,当数据或指令保存在 L1、L2 缓存时,物理核访问它们的延迟不超过 10 纳秒,速度非常快。所以我们想着如果Redis能把要运行的指令或存取的数据保存L1和L2缓存的话,就能快速访问这些指令和数据了。
但是 L1 和 L2 缓存的大小受限于处理器的制造技术,一般只有 KB 级别,存不下太多的数据。当L1、L2 缓存中没有所需的数据,应用程序就需要访问内存来获取数据。而访问内存的延迟就比访问缓存延迟要大得多,会对性能造成影响。
所以,在不同的物理核还会共享一个三级缓存(Level 3 cache,简称为 L3 cache)。L3 缓存能够使用的存储资源比较多,所以一般比较大,能达到几 MB 到几十 MB,这就能让应用程序缓存更多的数据。当 L1、L2 缓存中没有数据缓存时,可以访问 L3,尽可能避免访问内存。

# NUMA 架构
为了提升服务器的处理能力,服务器上通常还会有多个CPU处理器(多CPU Socket),每个处理器有自己的物理核(包括 L1、L2 缓存),L3 缓存,以及连接的内存,同时,不同处理器间通过总线连接。
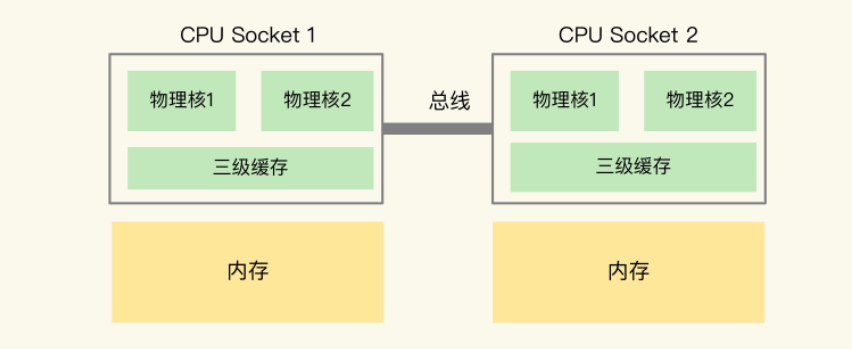
在多CPU架构上,应用程序上可以在不同的处理器上运行。在上图中,Redis可以在Socket 1上运行一段时间,然后再调用到Socket 2上运行。
注意点:如果应用程序先在一个 Socket 上运行,并且把数据保存到了内存,然后被调度到另一个 Socket 上运行,此时,应用程序再进行内存访问时,就需要访问之前 Socket 上连接的内存,这种访问属于远端内存访问。和访问 Socket 直接连接的内存相比,远端内存访问会增加应用程序的延迟。
在多 CPU 架构下,一个应用程序访问所在 Socket 的本地内存和访问远端内存的延迟并不一致,所以,我们也把这个架构称为非统一内存访问架构(Non-Uniform Memory Access,NUMA 架构)。
CPU架构对应用程序运行的影响总结如下:
- 充分利用 L1、L2 缓存,可以有效缩短应用程序的执行时间;
- 如果应用程序从一个 Socket 上调度到另一个 Socket 上,就可能会出现远端内存访问的情况,这会直接增加应用程序的执行时间。
# CPU多核对Redis性能的影响
单核CPU场景下:应用程序需要记录自身使用的软硬件资源信息(例如栈指针、CPU 核的寄存器值等),我们把这些信息称为运行时信息。同时,应用程序访问最频繁的指令和数据还会被缓存到 L1、L2 缓存上,以便提升执行速度。
多核CPU场景下:一旦应用程序需要在一个新的 CPU 核上运行,那么,运行时信息就需要重新加载到新的 CPU 核上。而且,新的 CPU 核的 L1、L2 缓存也需要重新加载数据和指令,这会导致程序的运行时间增加。
如果在 CPU 多核场景下,Redis 实例被频繁调度到不同 CPU 核上运行的话,那么,对 Redis 实例的请求处理时间影响就更大了。每调度一次,一些请求就会受到运行时信息、指令和数据重新加载过程的影响,这就会导致某些请求的延迟明显高于其他请求,相当于CPU的context switch次数比较多。
context switch 是指线程的上下文切换,这里的上下文就是线程的运行时信息。在 CPU 多核的环境中,一个线程先在一个 CPU 核上运行,之后又切换到另一个 CPU 核上运行,这时就会发生 context switch。
为了避免Redis总是在不同CPU核上来回调度执行,就需要把Redis实例和CPU核绑定,让一个Redis实例固定运行在一个CPU核上。
# CPU的NUMA 架构对 Redis 性能的影响
实际应用中,为了提升Redis的网络性能,会把操作系统的网络中断处理程序和CPU核绑定。这是为了避免网络中断处理程序在不同核上来回调度执行,能够有效提升Redis的网络处理性能。
但是要注意网络中断程序是要和Redis实例进行网络数据交互的:网络中断处理程序从网卡硬件中读取数据,并把数据写入到操作系统内核维护的一块内存缓冲区。内核会通过 epoll 机制触发事件,通知 Redis 实例,Redis 实例再把数据从内核的内存缓冲区拷贝到自己的内存空间。

在CPU的NUMA架构下,当网络中断处理程序、Redis 实例不绑定在同一个CPU 核会存在一个问题:Redis 实例读取网络数据时,就需要跨 CPU Socket 访问内存,这个过程会花费较多时间。
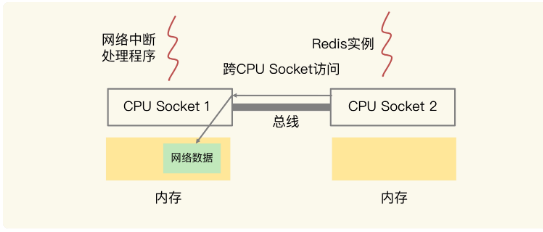
假如网络中断处理程序被绑在了 CPU Socket 1 的某个核上,而 Redis 实例则被绑在了 CPU Socket 2 上。此时,网络中断处理程序读取到的网络数据,被保存在 CPU Socket 1 的本地内存中,当 Redis 实例要访问网络数据时,就需要 Socket 2 通过总线把内存访问命令发送到 Socket 1 上,进行远程访问,时间开销比较大。
所以,为了避免 Redis 跨 CPU Socket 访问网络数据,我们最好把网络中断程序和 Redis 实例绑在同一个 CPU Socket 上,这样一来,Redis 实例就可以直接从本地内存读取网络数据了。
