 深入客户端
深入客户端
# 一、分区分配策略
kafka提供了消费者客户端参数partition.assignment.strategy来设置消费者与订阅主题之间得分区分配策略,默认情况下,参数的值org.apache.kafka.clients.consumer.RangeAssignor,就是采用的RangeAssignor分配策略,除此以外kafka还提供RoundRobinAssignor和StickyAssignor分配策略。
# 1、RangeAssignor分配策略
RangeAssignor分配策略的原理是消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,来保证分区均匀分配给所有的消费者。
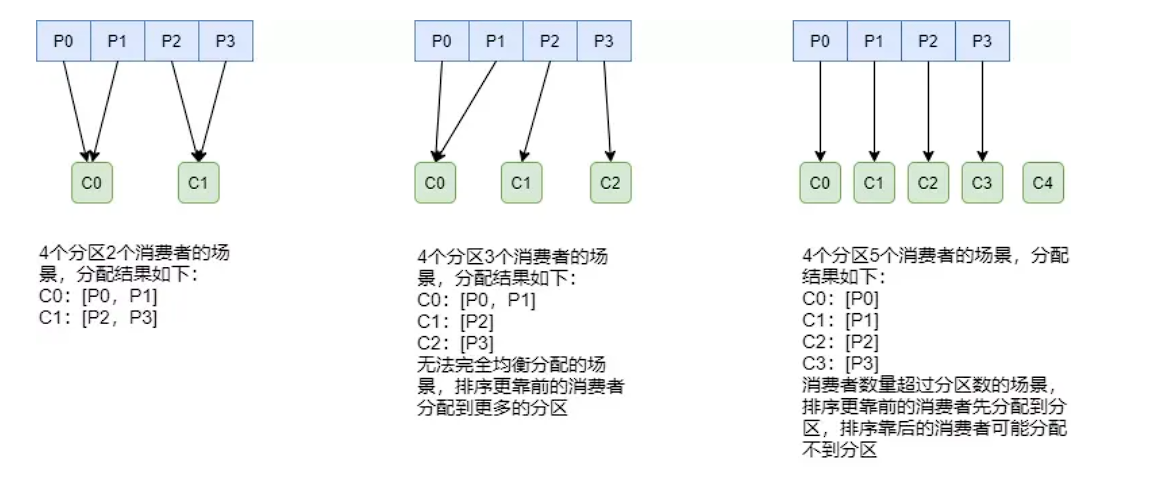
这种分配方式明显的一个问题是随着消费者订阅的Topic的数量的增加,不均衡的问题会越来越严重
# 2、RoundRobinAssignor分配策略
RoundRobinAssignor分配策略的原理是将消费组内所有消费组以及消费者订阅的所有主题的分区按照字典序排列,然后通过轮询方式逐个将分区依次分配给每个消费者。
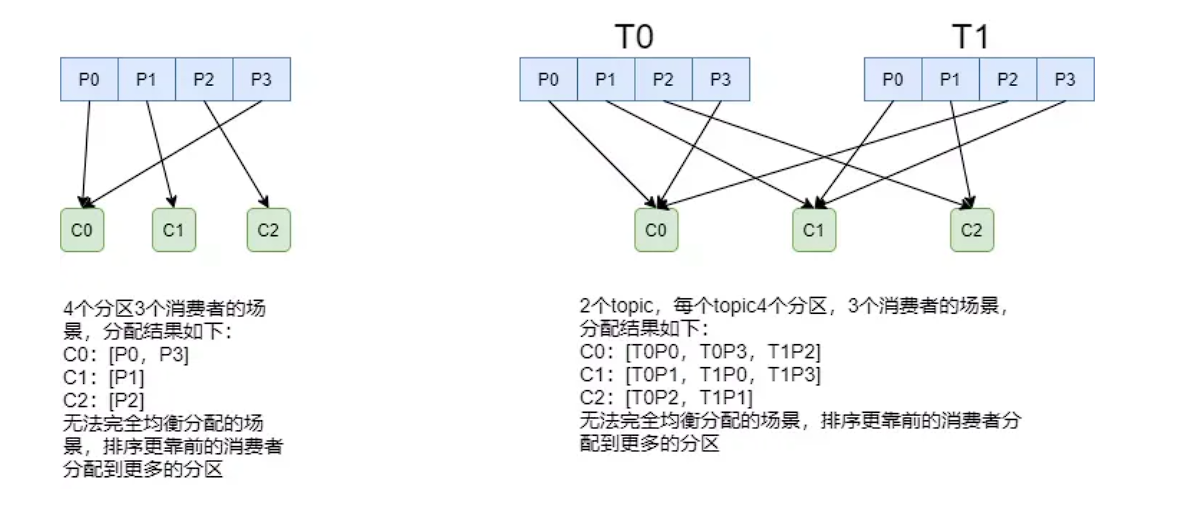
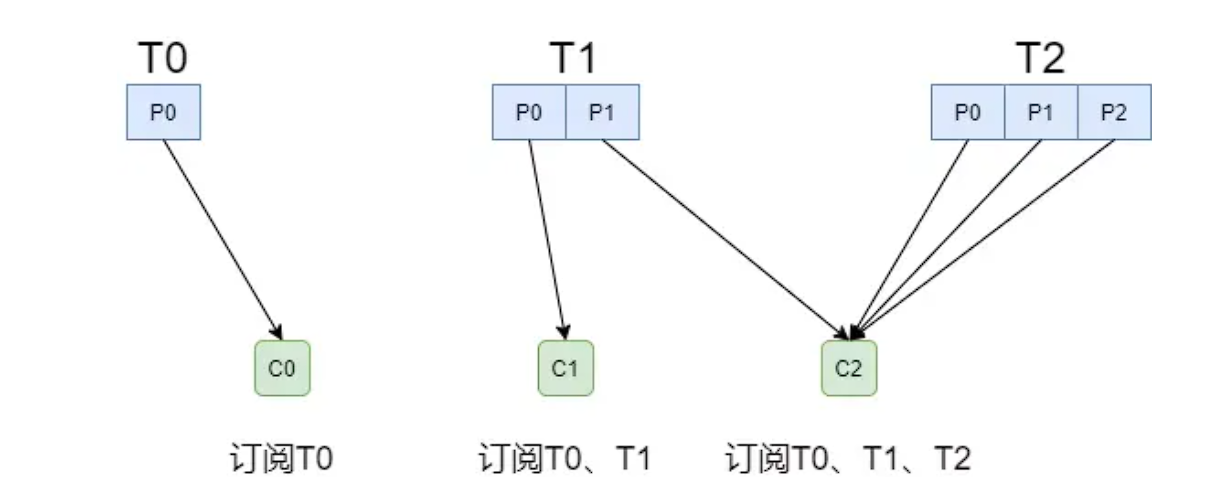
但是如果每个消费者订阅的主题不同,就可能造成分配不均的情况:假设有三个消费者分别为C0、C1、C2,有3个Topic T0、T1、T2,分别拥有1、2、3个分区,并且C0订阅T0,C1订阅T0和T1,C2订阅T0、T1、T2,那么RoundRobinAssignor的分配结果如下:
# 3、StickyAssignor分配策略
StickyAssignor分区分配算法,目的是在执行一次新的分配时,能在上一次分配的结果的基础上,尽量少的调整分区分配的变动,节省因分区分配变化带来的开销,它的主要目的是:
- 分区的分配尽量的均衡。
- 每一次重分配的结果尽量与上一次分配结果保持一致。
假设消费组有3个消费者(C0,C1和C2),都订阅了4个主题(T0、T1、T2、T3),并且每个主题有两个分区:
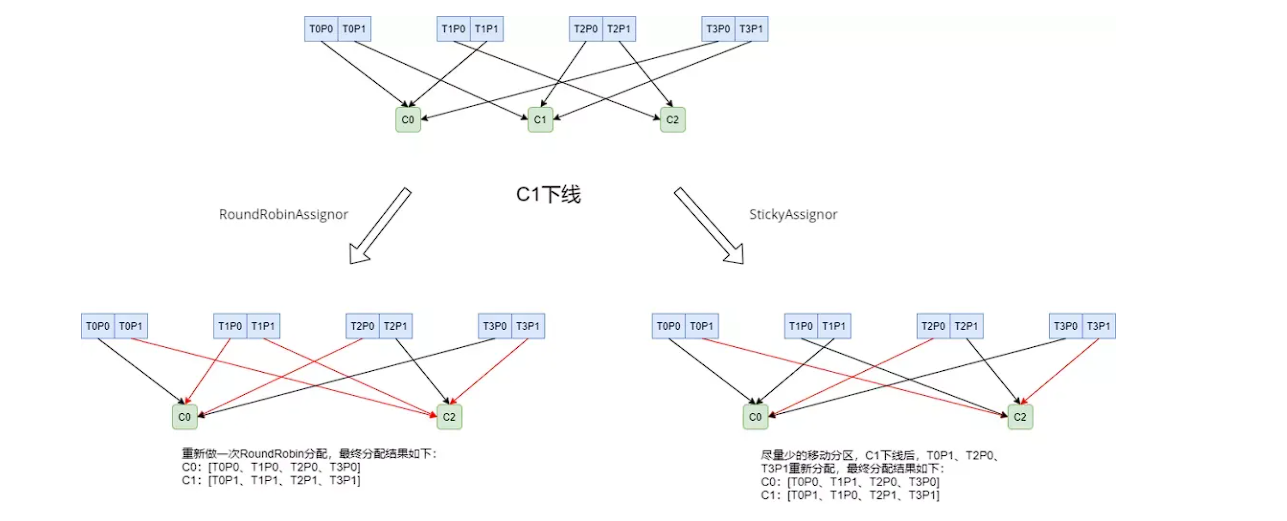
RoundRobinAssignor分配策略会按照消费者C0和C2进行重新轮询分配,但是StickyAssignor分配策略会尽可能让前后两次分配相同,进而减少系统资源的损耗和其他异常情况的发生。
# 二、_consumer_offsets
# 1、消息格式
位移提交的内容最终会保存到Kafka的内部主题_consumer_offsets中,其中OffsetCommitRequest请求格式如下:
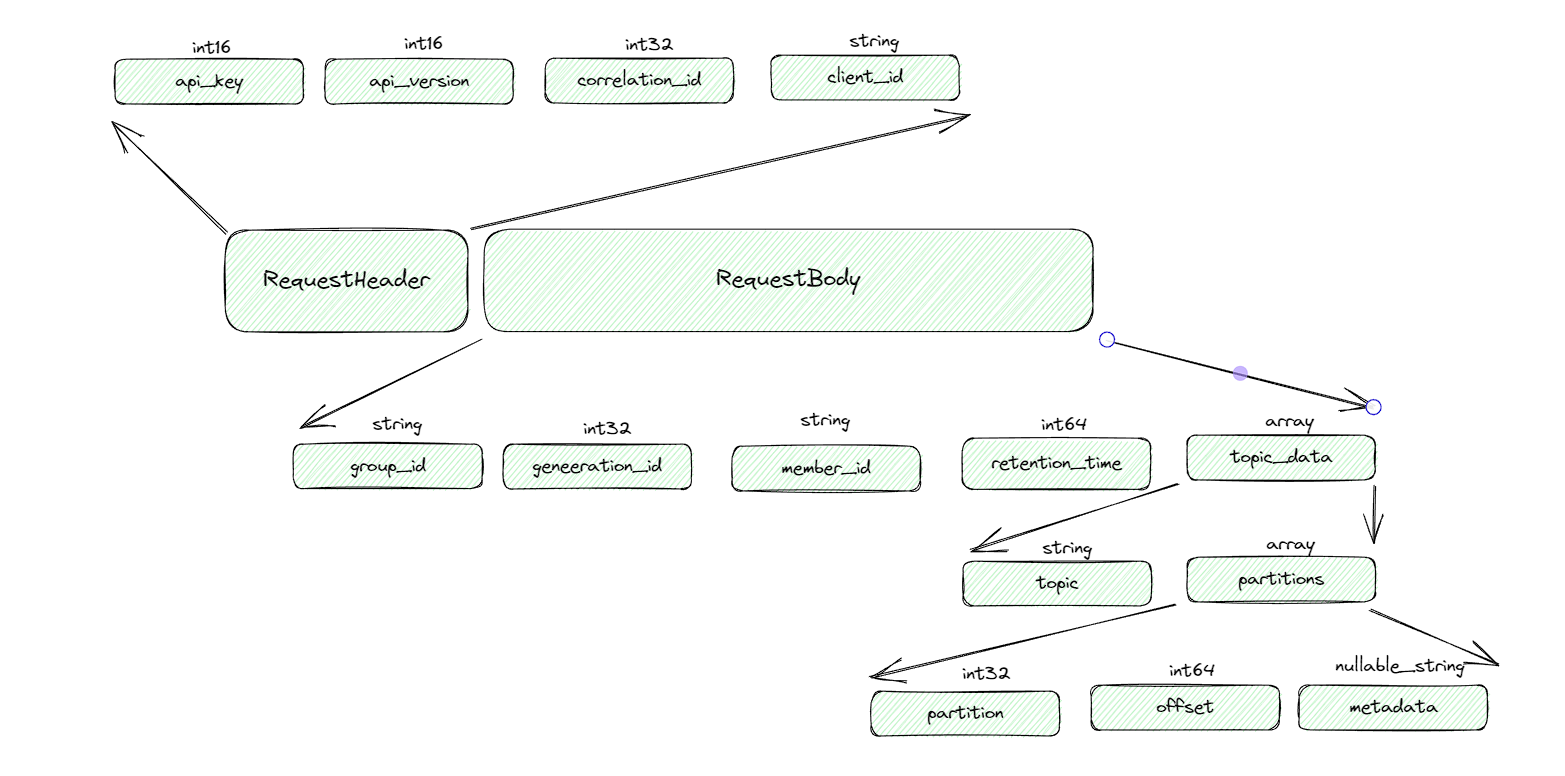
retention_time:表示当前提交的消费位移所能保留的时长,如果是定时任务消费消息之后保存了消费位移,但是下一次执行的时间间隔超过这个时间,就会导致原来的位移消息丢失。
和消费位移对应的消息只定义了key和value字段的具体内容,不依赖具体版本的消息格式:
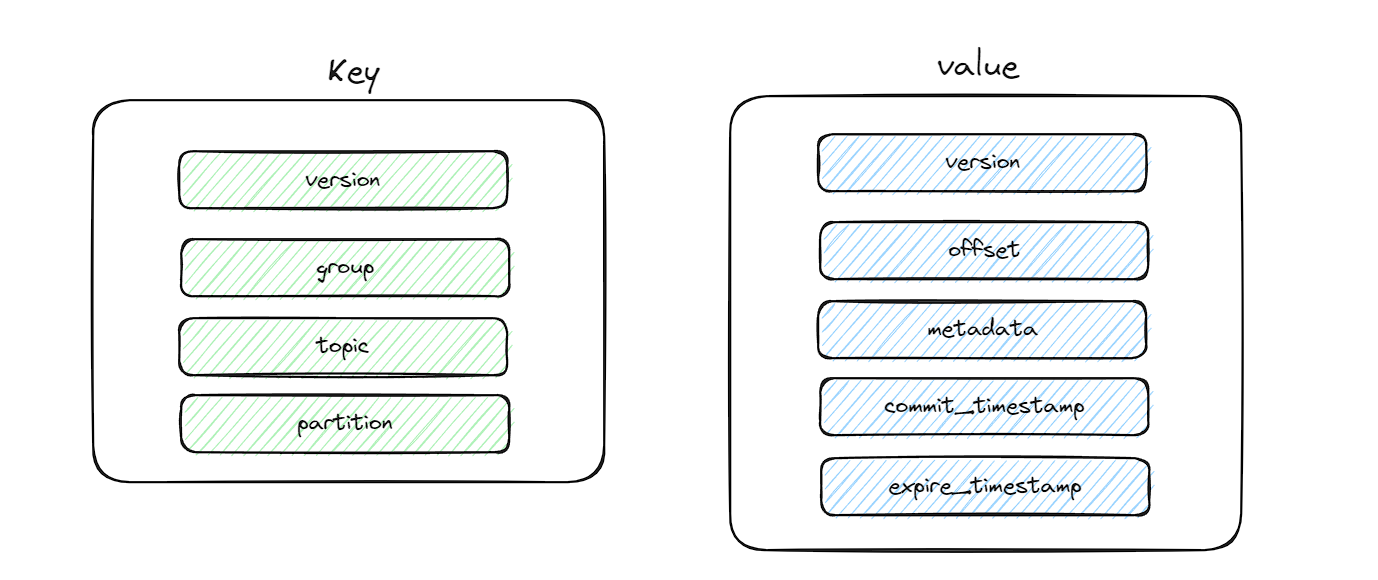
- key
version:value的version对应group:消费组,确定这条消息所要存储的分度topic:主题名称partition:分区编号
- value
version:key的version对应offset:消费位移metadata:元数据信息commit_timestamp:位移提交时间expire_timestamp:位移超时时间戳
# 2、何时创建内部主题
当 Kafka 集群中的第一个 Consumer 程序启动时,Kafka 会自动创建位移主题。并且这个主题的默认分区数是50,副本数是3。
不建议手动去创建这个主题,应该交由kafka内部管理。
# 3、何时写入位移
Kafka Consumer 提交位移的方式有两种:
- 自动提交位移
- 手动提交位移
针对自动提交位移,Consumer 端有个参数叫 enable.auto.commit,如果值是 true,则 Consumer 在后台默默地为你定期提交位移,提交间隔由一个专属的参数 auto.commit.interval.ms 来控制。
但是如果使用自动提交会存在一个问题:只要 Consumer 一直启动着,它就会无限期地向位移主题写入消息。也就是比如现在位移是100,假设现在没有消息写入,Consumer会一直写入消息。
# 4、如何删除重复位移
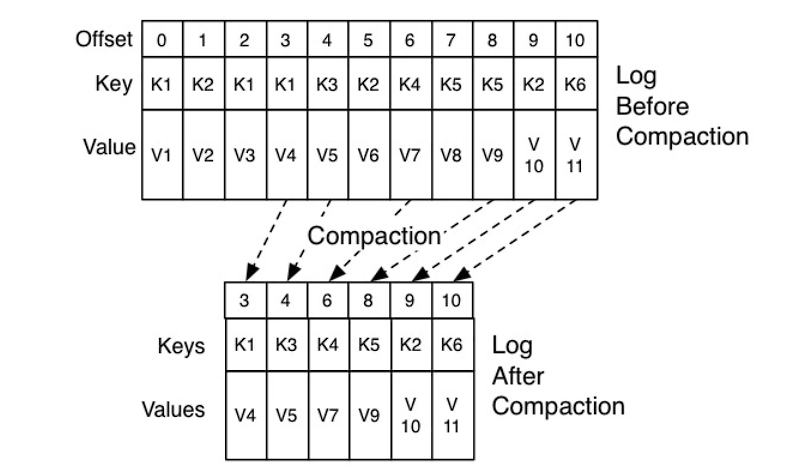
由于自动提交会重复提交位移,对于 Kafka 只需要保留这类消息中的最新一条就可以了,之前的消息都是可以删除的。这就要求 Kafka 必须要有针对位移主题消息特点的消息删除策略。
Kafka 使用 Compact 策略来删除位移主题中的过期消息,避免该主题无限期膨胀,具体实例如下:
对于同一个 Key 的两条消息 M1 和 M2,如果 M1 的发送时间早于 M2,那么 M1 就是过期消息。Compact 的过程就是扫描日志的所有消息,剔除那些过期的消息,然后把剩下的消息整理在一起。
# 三、事务
消息中间件的消息传输保障有三个层级:
at most once:至多一次,消息可能丢失,但绝对不会重复传输at leat once:最少一次,消息绝不会丢失,但可能会重复传输exactly once:恰好一次,每条消息肯定会被传输一次且仅传输一次
kafka为了保证消息的EOS,引入了幂等和事务两个特性:
# 1、幂等
所谓幂等简单来说就是对接口的多次调用所产生的结果和调用一次是一致的,生产者在进行重试的时候有可能会重复写入消息,而kafka的幂等性功能就可以避免这样的情况。
每个新的生产者实例化的时候都会分配一个PID,这个PID对用户而言是完全透明的,对于每个PID消息发送到的每一个分区都有对应的序列号,这些序列号从0开始单调递增,生产者每发送一条消息,对应的<PID,分区>的序列号的数值会加1,具体判断逻辑如下(SN_new表示新的序列号,SN_old表示旧的序列号):
- SN_new = SN_old + 1,正常接受
- SN_new < SN_old + 1,说明消息被重复写入
- SN_new < SN_old + 1,说明消息丢失
# 2、事务
幂等性并不能跨多个分区运作,事务可以弥补这个缺陷,事务可以保证对多个分区写入操作的原子性。
properties.put("transactional.id", "transactional")