基础概念
基础概念
# 一、损失函数
假设有一个线性函数如下:
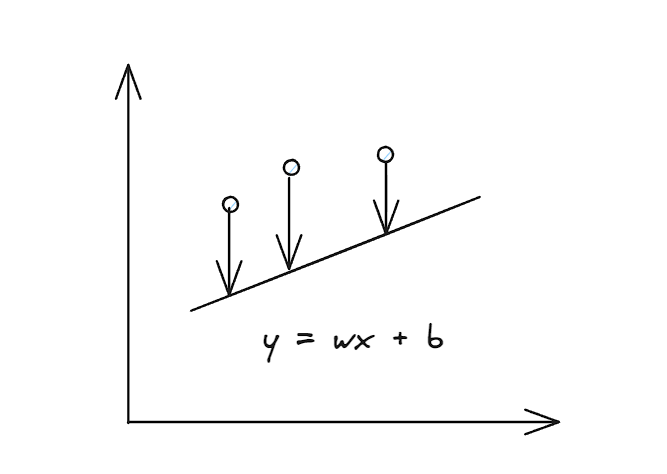
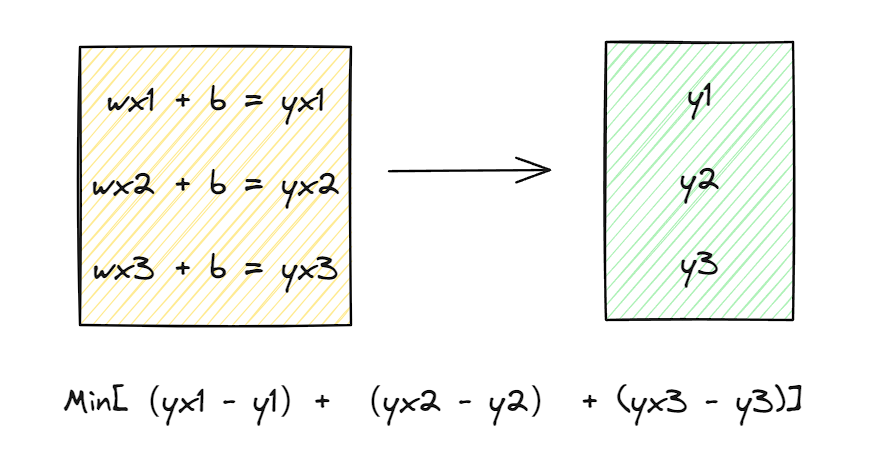
为了让函数更好描述三个点的函数变化,我们要使得计算后的yx和实际的yi偏差更小才行:
一般来说例如最小二乘法计算损失函数:
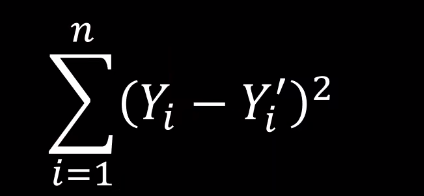
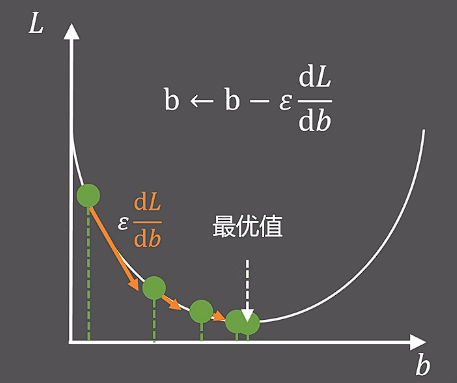
# 二、梯度下降算法
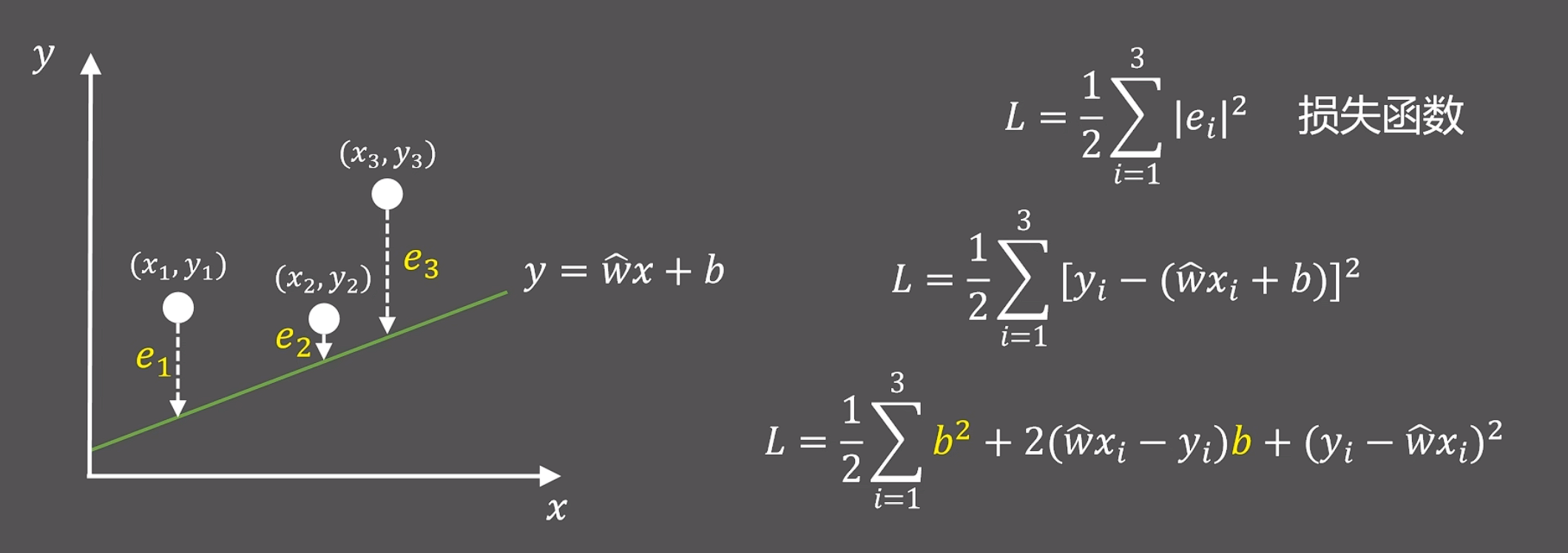
章节一中我们想要损失函数最小,而损失函数是一个二维函数,我们想让这个二维函数最小:
# 三、反向传播算法
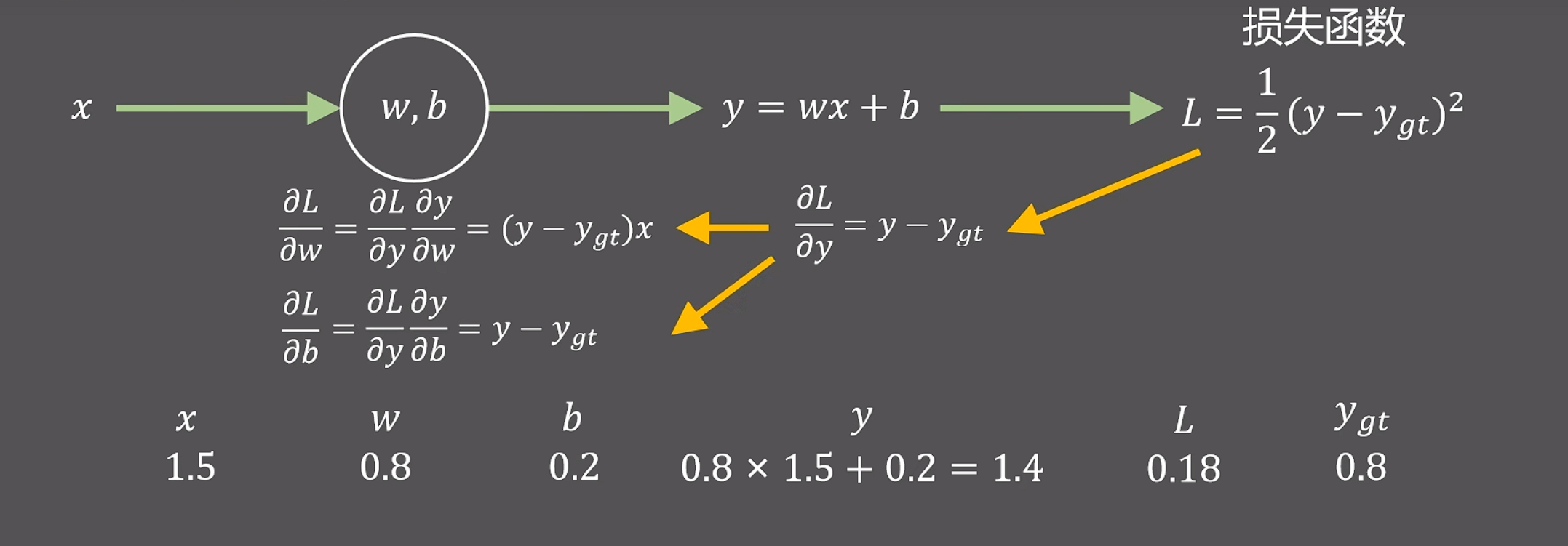
从损失函数,利用链式求导的方式计算出特定情况下w和b的偏导:

沿着黄色方向向后计算的过程就是反向传播
# 四、准确率、精确率、召回率等指标
# 1、TP、TN、FP、FN
| Positive | Negative | |
|---|---|---|
| True | True Positive (TP) | True Negative(TN) |
| False | False Positive (FP) | False Negative (FN) |
True Positive(真正,TP):将正类预测为正类数
True Negative(真负,TN):将负类预测为负类数
False Positive(假正,FP):将负类预测为正类数误报 (Type I error)
False Negative(假负,FN):将正类预测为负类数→漏报 (Type II error)
# 2、P和N
- 阳性Positive(正),表示本身为正确的样本
- 阴性Negative(负),表示本身为错误的样本
综上,我们可以得到:
- P = TP + FN
- N = FP + TN
# 3、准(正)确率
反映分类器或者模型对整体样本判断正确的能力,也就是正确样本识别率加上错误样本识别率
ACC = TP + TN / (TP + FN + FP + TN)
# 4、精确率precision
分为正例的样本占分类后为正例的比例。
precision = TP / (TP + FP)
# 5、召回率recall
分为正例的样本占本身为正例的比例。
recall = TP / (TP + FN)= TP / P
# 6、F1
该值是精确率precision和召回率recall的加权调和平均。值越大,性能performance越好。F值可以平衡precision少预测为正样本和recall基本都预测为正样本的单维度指标缺陷。计算公式如下:

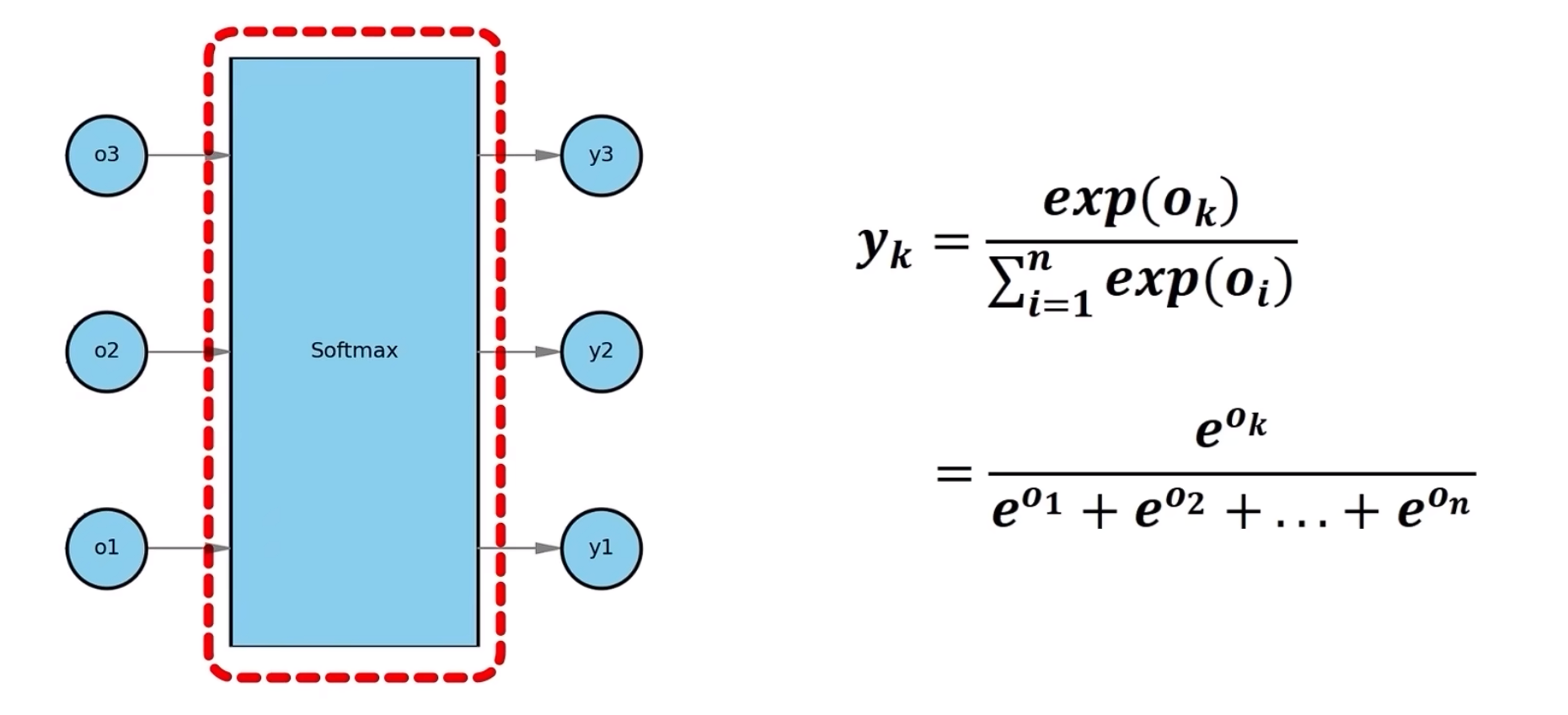
# 四、softmax
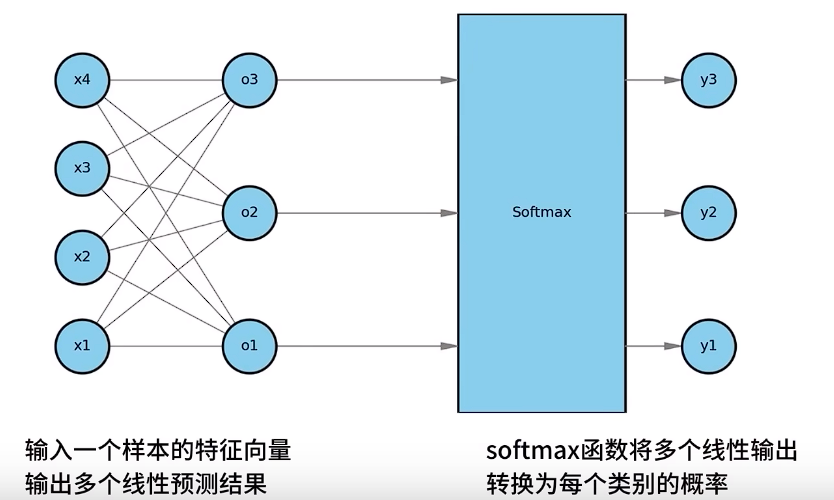

上述的情况可以转换为如下的向量计算:
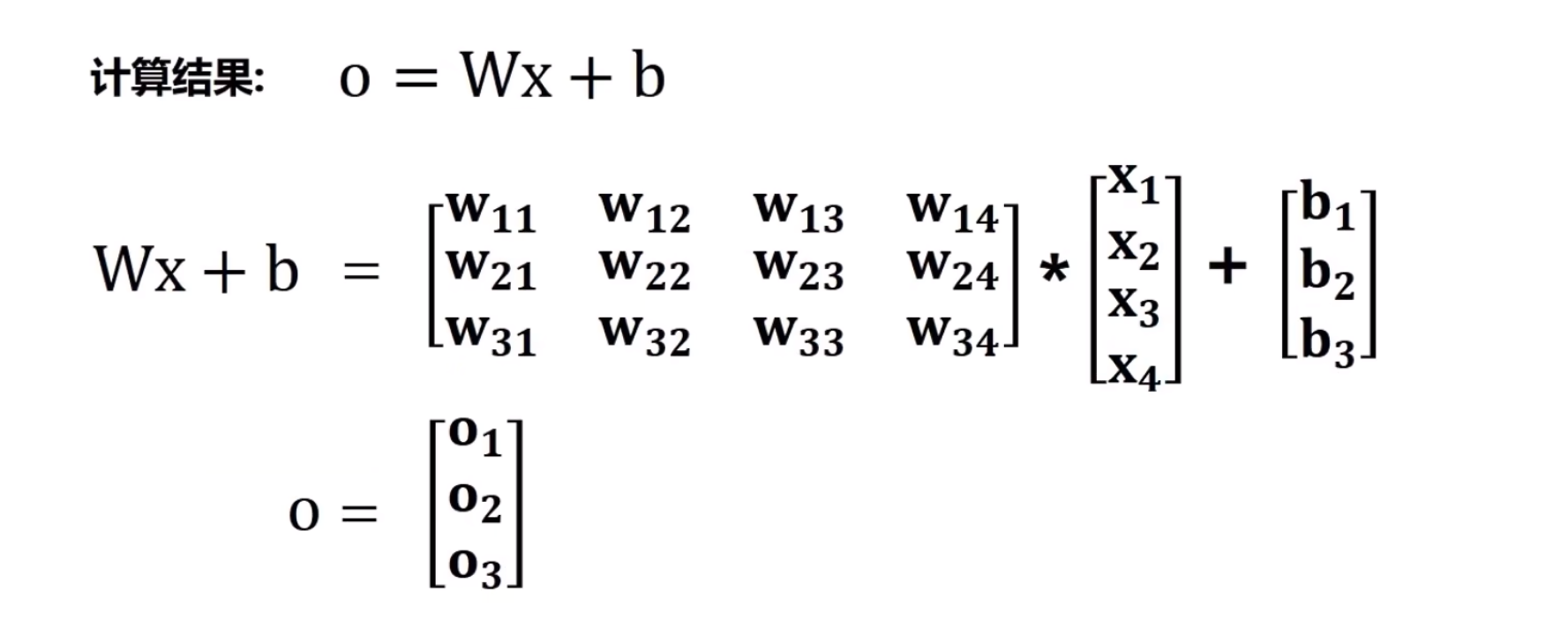
接下来将结果o1、o2、o3代入softmax中,得到y1,y2,y3,然后分别计算概率
# 五、CNN
概述
人类识别一个物体是通过一些特征来进行识别(眼睛、鼻子等),计算机想要识别一个物体,就需要对物体的特征进行分析和归类。
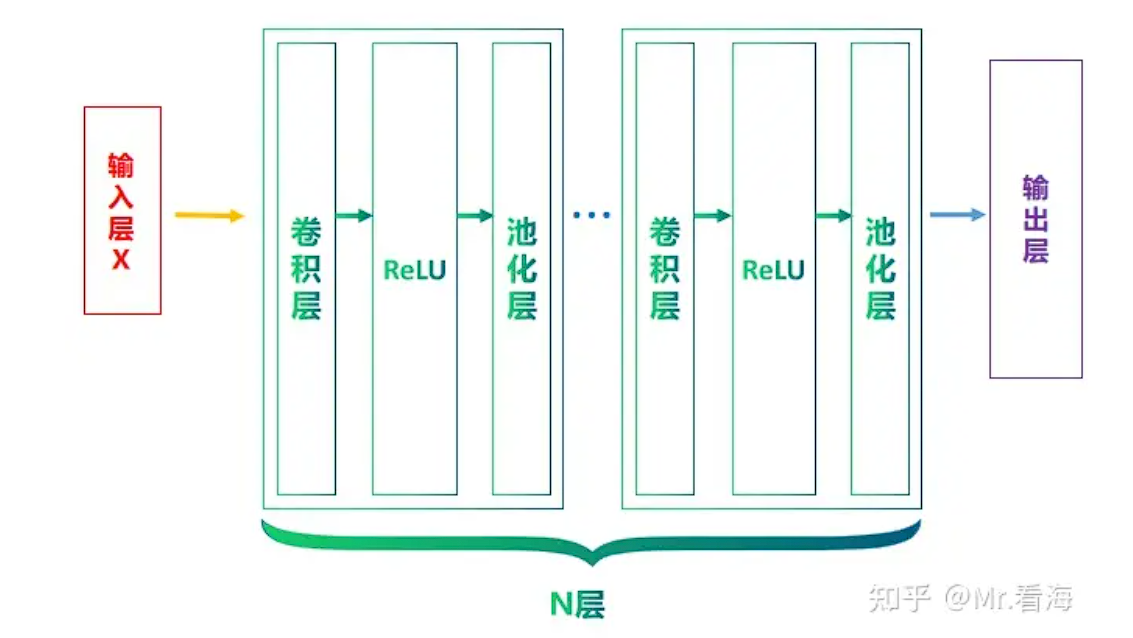
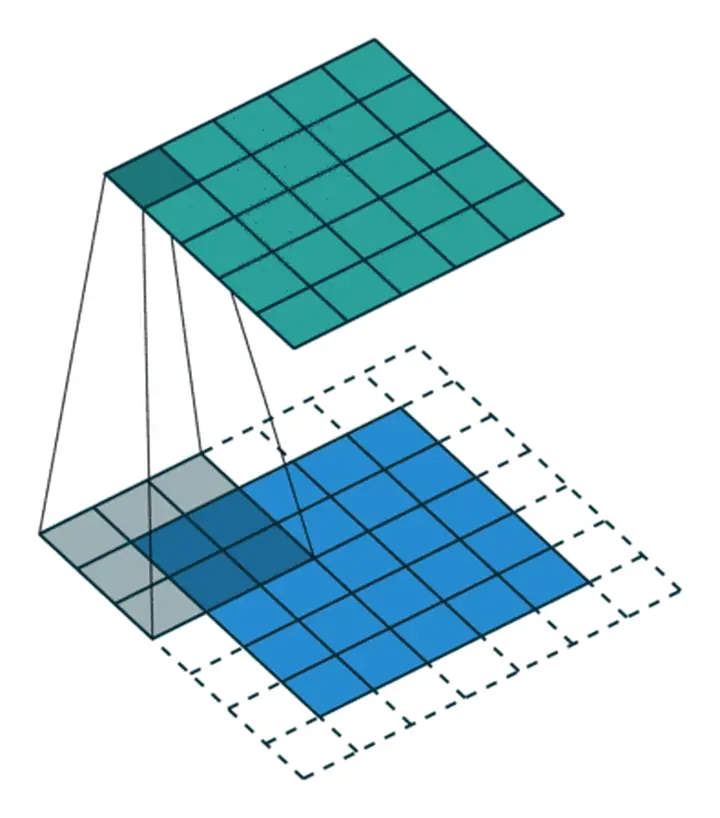
# 1、卷积层
卷积
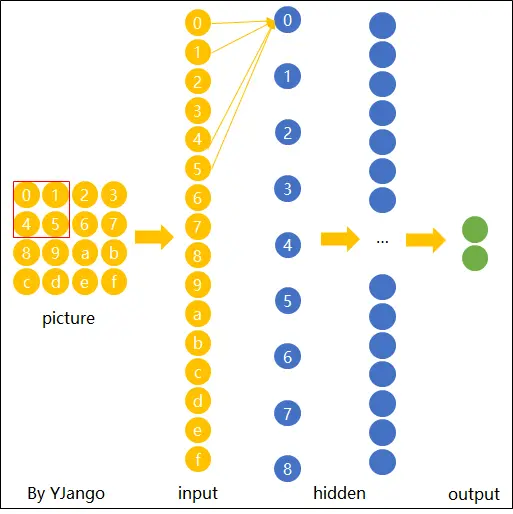
步长
滑动卷积核时,我们会先从输入的左上角开始,每次往左滑动一列或者往下滑动一行逐一计算输出,我们将每次滑动的行数和列数称为Stride。
填充
# 2、激活层
ReLU函数是一个非线性函数,只保留正数元素,将负数元素设置为0。
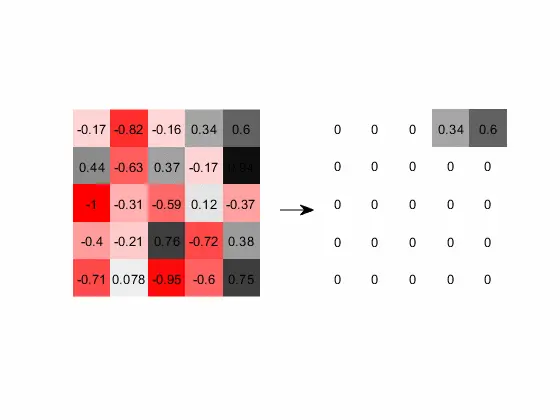
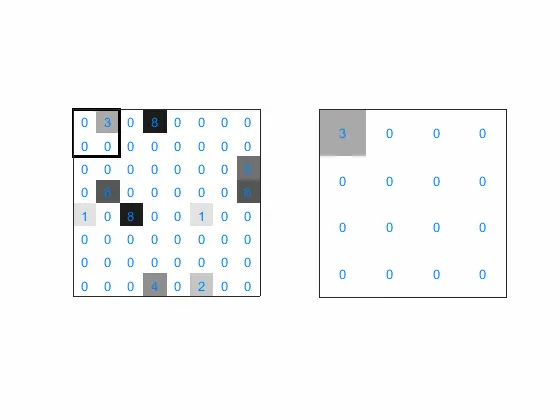
# 3、池化层
池化层的主要作用是对非线性激活后的结果进行降采样,以减少参数的数量,避免过拟合,并提高模型的处理速度。
池化层主要采用最大池化(Max Pooling)、平均池化(Average Pooling)等方式,对特征图进行操作:
# 六、RNN
概述
循环神经网络(Recurrent Neural Network, RNN)是一类具有内部环状连接的人工神经网络,用于处理序列数据。
工作原理
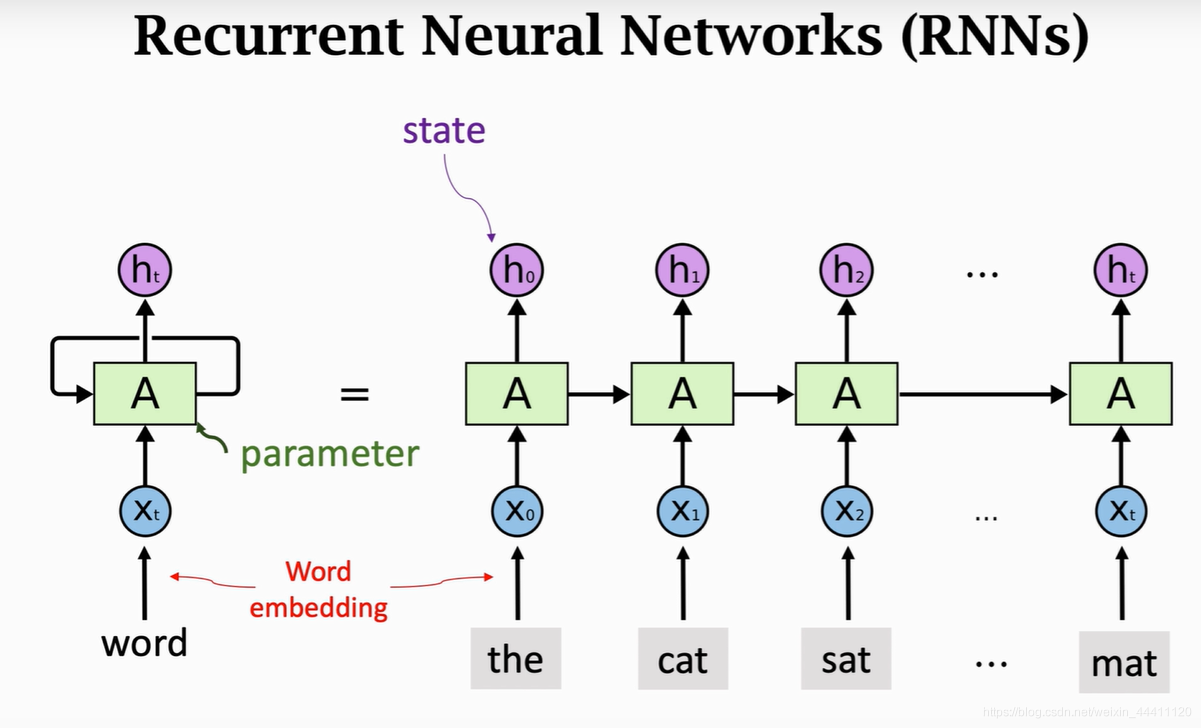
- 输入层:RNN能够接受一个输入序列(例如文字、股票价格、语音信号等)并将其传递到隐藏层。
- 隐藏层:隐藏层之间存在循环连接,使得网络能够维护一个“记忆”状态,这一状态包含了过去的信息。这使得RNN能够理解序列中的上下文信息。
- 输出层:RNN可以有一个或多个输出,例如在序列生成任务中,每个时间步都会有一个输出。
相当于后续的ht包含了上一代的信息,但是可能会存在梯度消失或梯度爆炸问题
# 七、LSTM
背景
由于RNN只能保留早期记忆,我们希望我们的记忆能够取舍一下,选择性留下重要的,丢弃不重要的。
工作原理
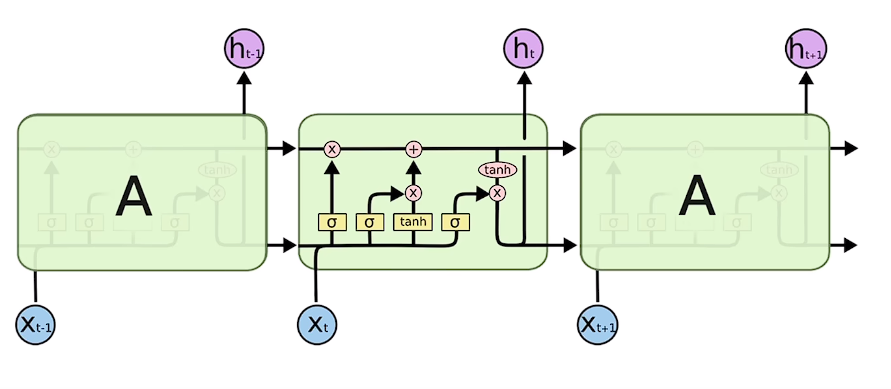
- 输入门(input gate): 决定了当前输入信息是否写入记忆细胞,也就是说,能够控制输入信息对记忆细胞的影响。
- 遗忘门(forget gate): 决定了记忆细胞中的信息是否被遗忘,也就是说,能够控制记忆细胞中保存的信息会不会消失。
- 输出门(output gate): 决定了记忆细胞中的信息是否输出,也就是说,能够控制记忆细胞中保存的信息会不会对后面的网络层造成影响。
# 八、自注意力机制
# 1、流程
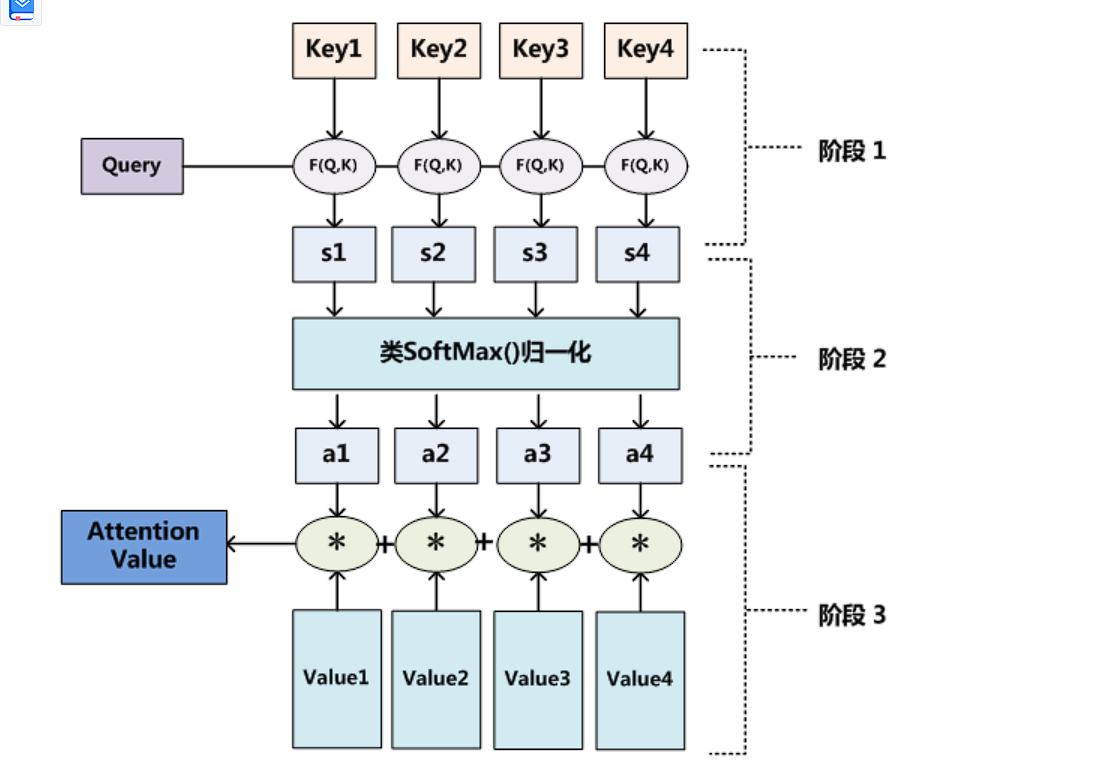
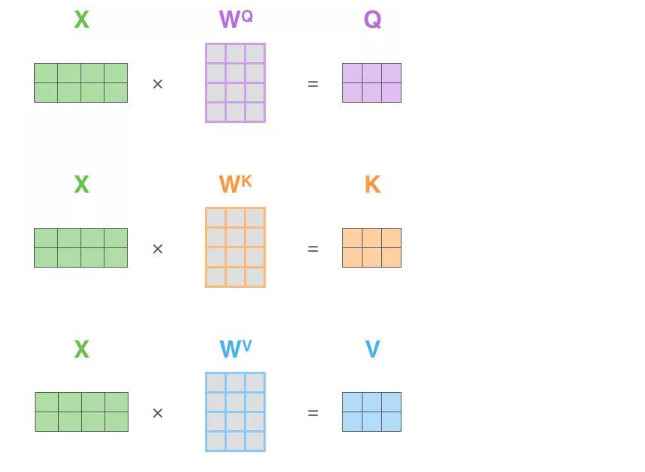
# 2、Q、K、V
- Q = x * wq
- K = x * wk
- V = x * wv
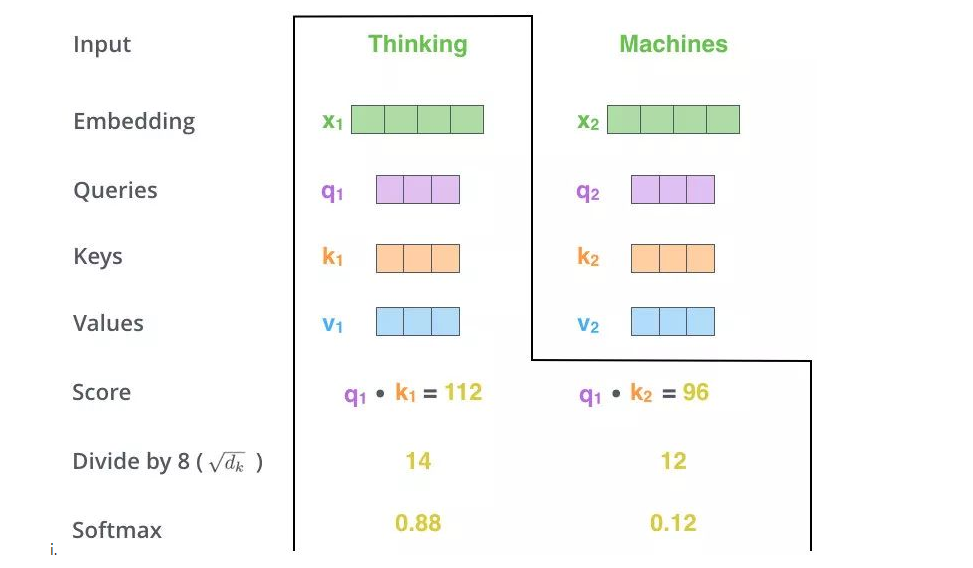
# 3、Q和K计算内积
s1 = q1 * k1
s2 = q1 * k2
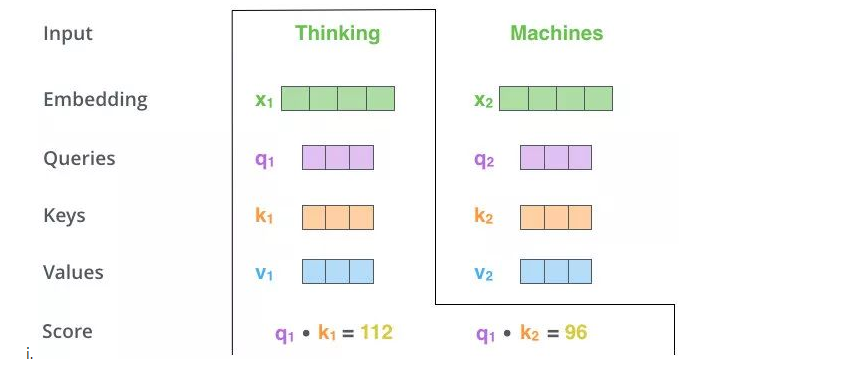
# 4、softmax
# 5、qk的内积再和value内积
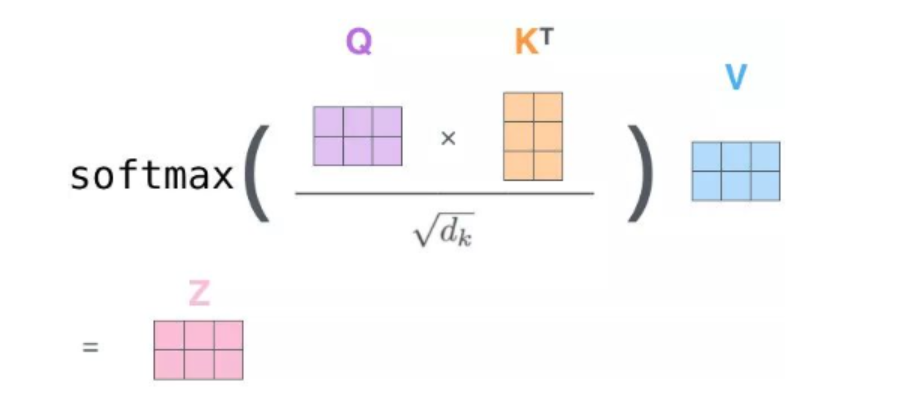
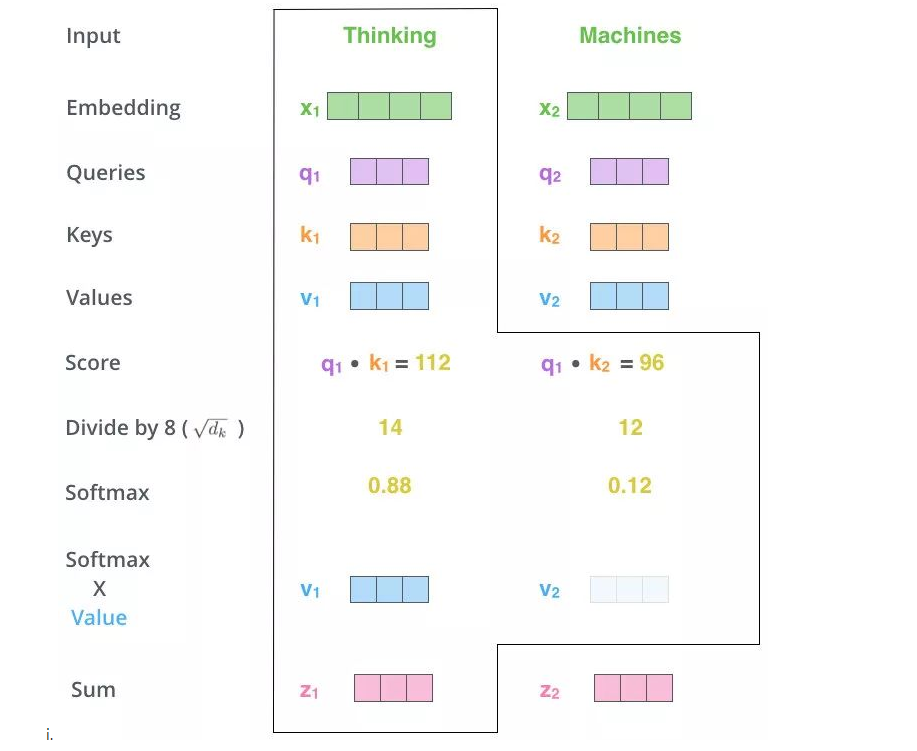
# 6、全流程
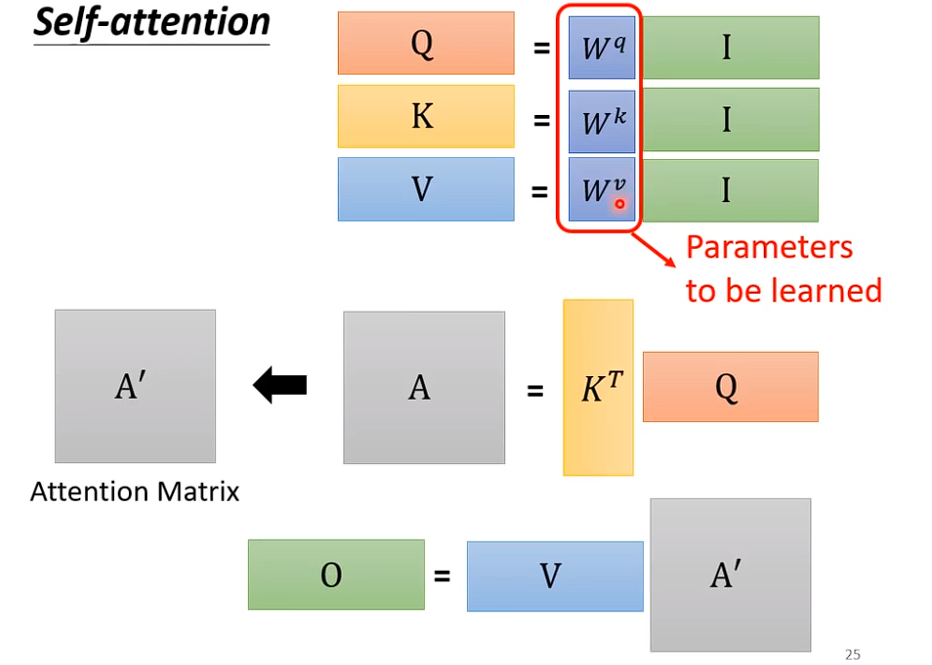
输入是I,输出是O
# 九、多头注意力机制
流程
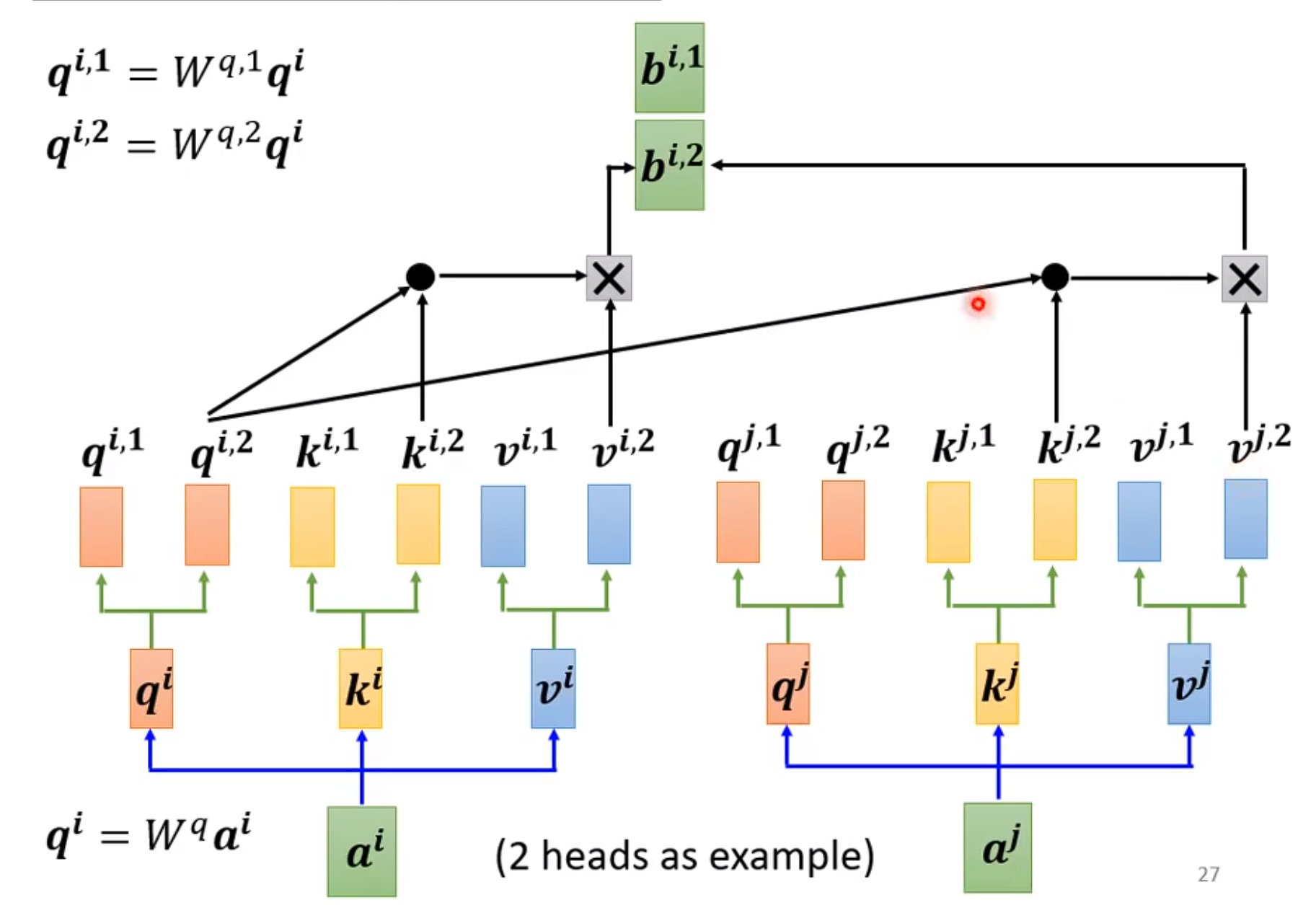
相当于我们把注意力机制在一维度的层面上,扩展到多层面维度上。
缺点
无法体现向量的位置关系,即使把文字顺序打散,最终得到的分数也是一样的。
# 十、Transformer
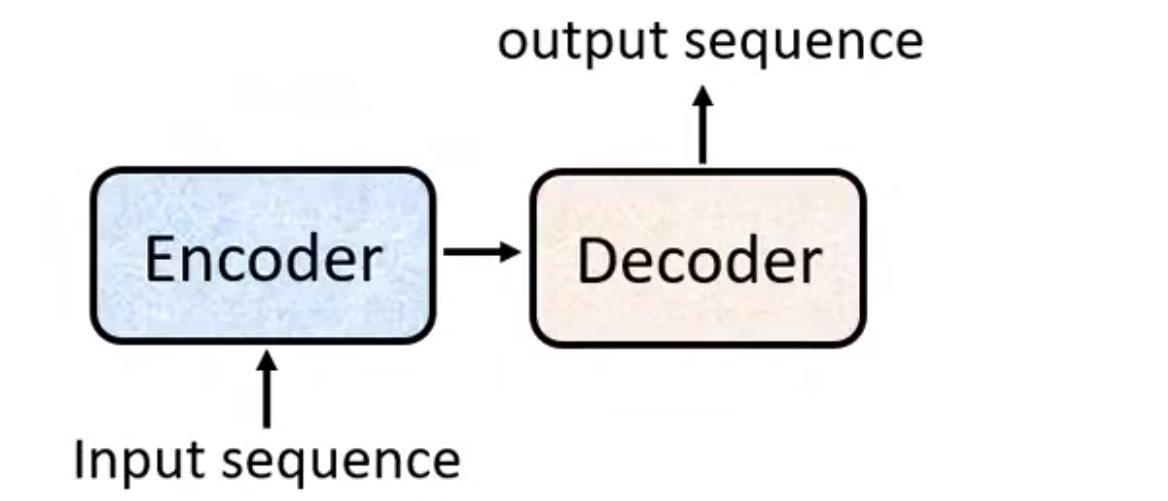
# 1、Seq2seq
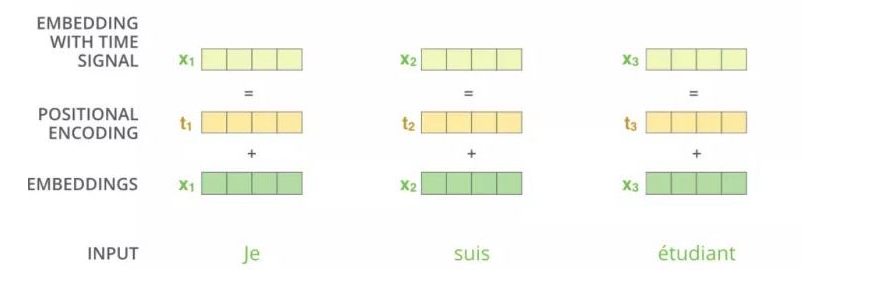
# 2、位置编码
概述
以前一个词向量只是用来表示这个词,但是没有表示这个词在整个句子中的位置关系,现在我们通过在词向量的基础上加了一个位置编码得到一个带有位置编码的词向量,这个新的词向量既能表示这个词,也能表示这个词在整个句子中的位置关系。
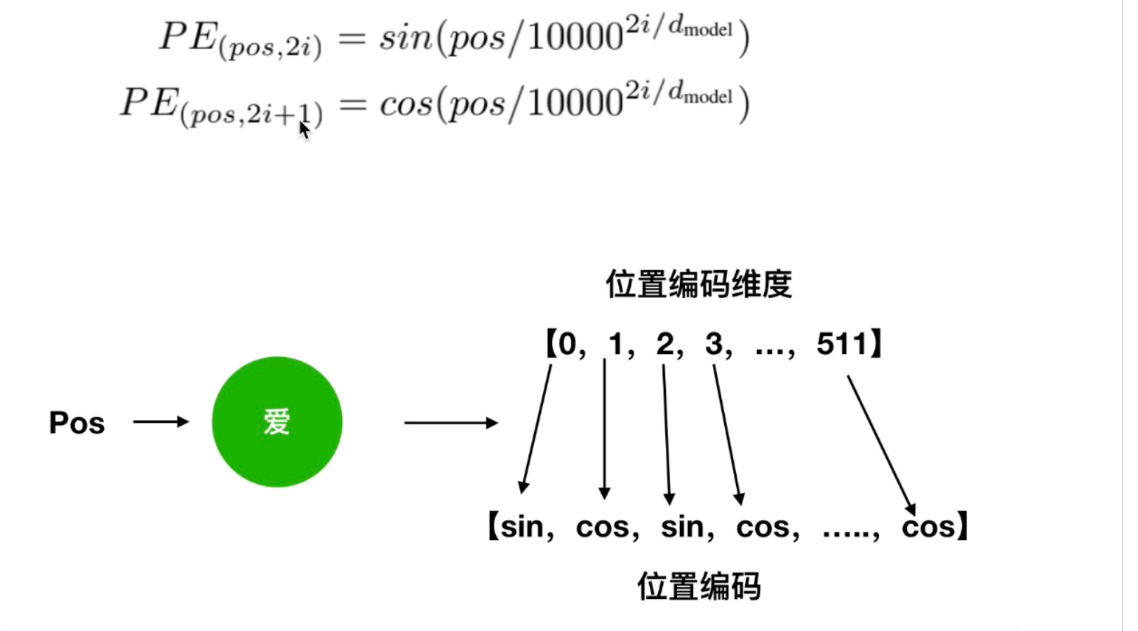
公式

# 3、Encoder
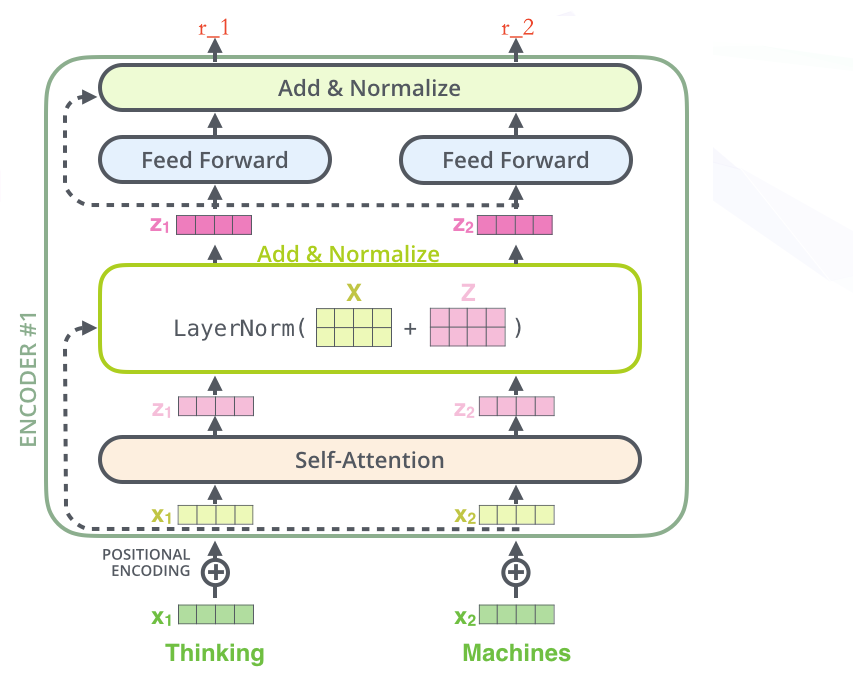
- 绿色的 x1(词向量,可以通过 one-hot、word2vec 得到)+ 叠加位置编码(给 x1 赋予位置属性)得到黄色的 x1
- 输入到 Self-Attention 子层中,做注意力机制(x1、x2 拼接起来的一句话做),得到 z1(x1 与 x1,x2拼接起来的句子做了自注意力机制的词向量,表征的仍然是 thinking),也就是说 z1 拥有了位置特征、句法特征、语义特征的词向量
- 残差网络(避免梯度消失,w3(w2(w1x+b1)+b2)+b3,如果 w1,w2,w3 特别小,0.0000000000000000……1,x 就没了。【w3(w2(w1x+b1)+b2)+b3+x】,利用x来兜底),归一化(LayerNorm),做标准化(避免梯度爆炸),得到了深粉色的 z1
- Feed Forward,Relu(w2(w1x+b1)+b2),(前面每一步都在做线性变换,wx+b,线性变化的叠加永远都是线性变化(线性变化就是空间中平移和扩大缩小),通过 Feed Forward中的 Relu 做一次非线性变换,这样的空间变换可以无限拟合任何一种状态了),得到 r1(是 thinking 的新的表征)
# 4、Decoder
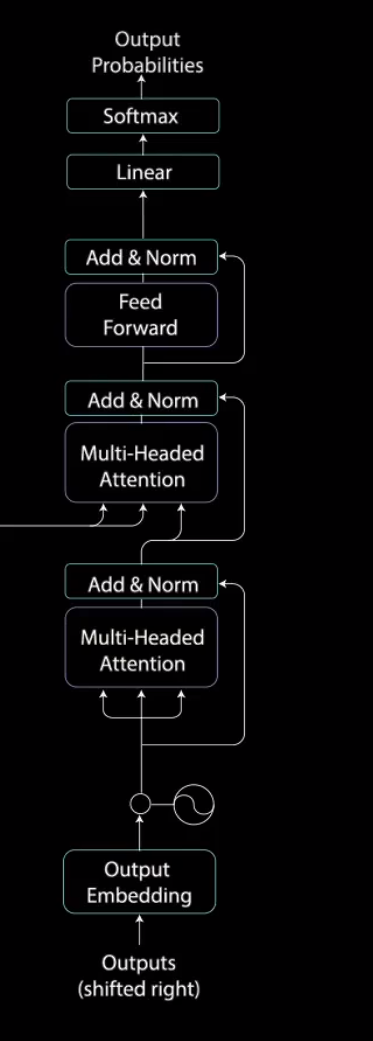
- 输出 + 位置编码
- 多头掩码注意机制:多头注意力机制 + 掩码(防止未来的词对现有的词影响)
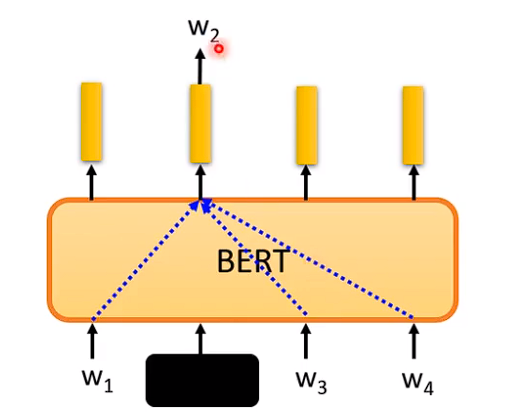
# 十一、Bert
# 1、掩码输入
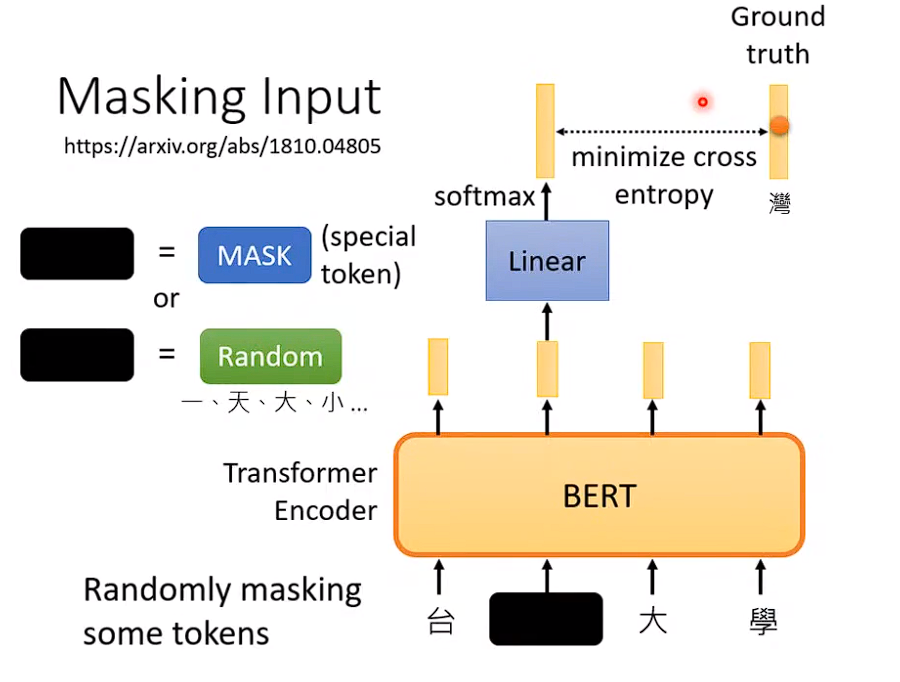
随机盖住一个词,然后模型根据左右文字,来猜盖住的单词是什么,类似做一个完型填空。
# 2、next Sentence Prediction
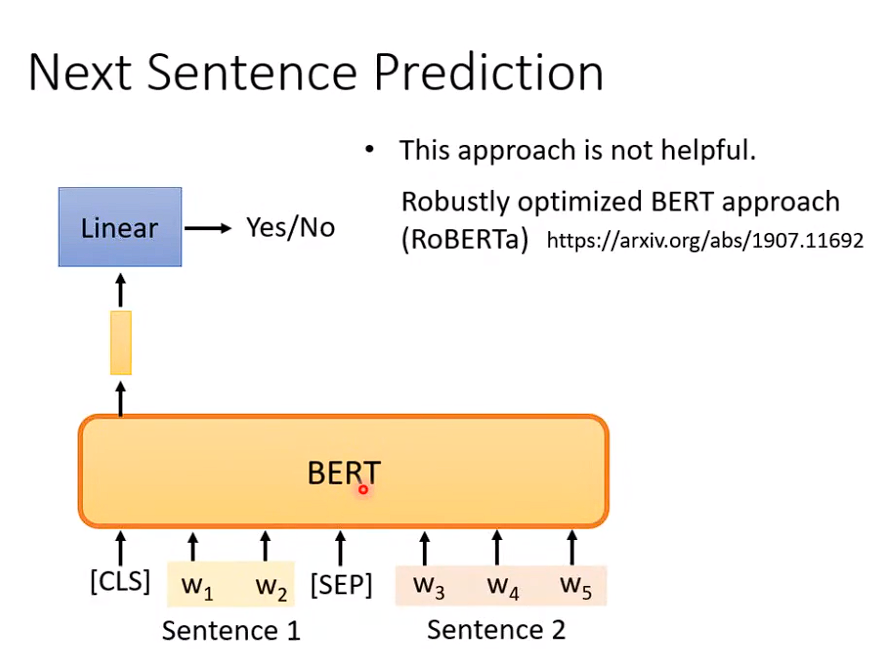
两个句子,判断两个句子是否相识。
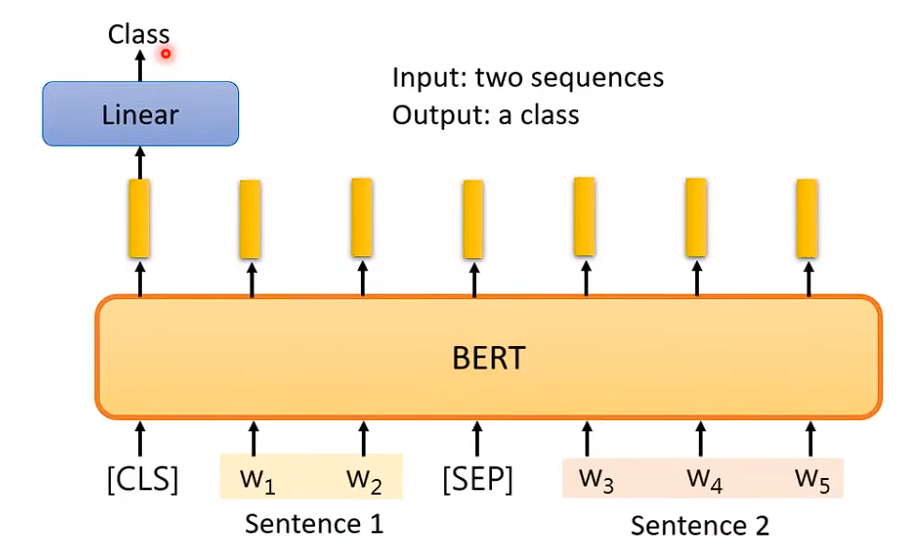
# 3、Bert的使用
输入两个句子,输出一个类别
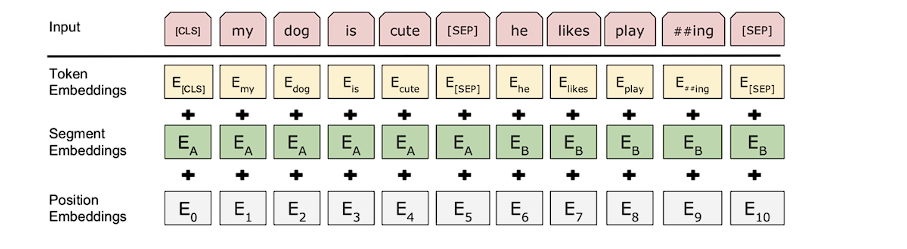
- Token Embeddings:字向量。
- Segment Embeddings:部分编码。因为Bert在训练时,有一种模式是输入两句话来判断它们的相似度,部分编码的作用就是区别每个字属于哪句话。如图前一句标为了A,后一句标为了B。
- 位置编码: 因为在计算注意力矩阵时是直接相乘,并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,它都会得到类似的结果。所以它本身是不能利用单词的顺序信息的,因此需要在输入中添加位置Embedding,否则它就是一个词袋模型。为了解决这个问题,论文中在编码词向量时引入了位置编码的特征这样就能区分不同位置的单词了。
# 4、Bert工作流程