 日志存储
日志存储
# 一、文件目录布局
Kafka的消息以主题为基本单位进行归类的,各个主题又可以分为一个或多个分区。
不考虑多个副本的情况,其中一个分区对应一个日志(Log),为了让日志文件过大,将Log切分为多个LogSegment,便于消息的维护和清理。整体目录结构如下:
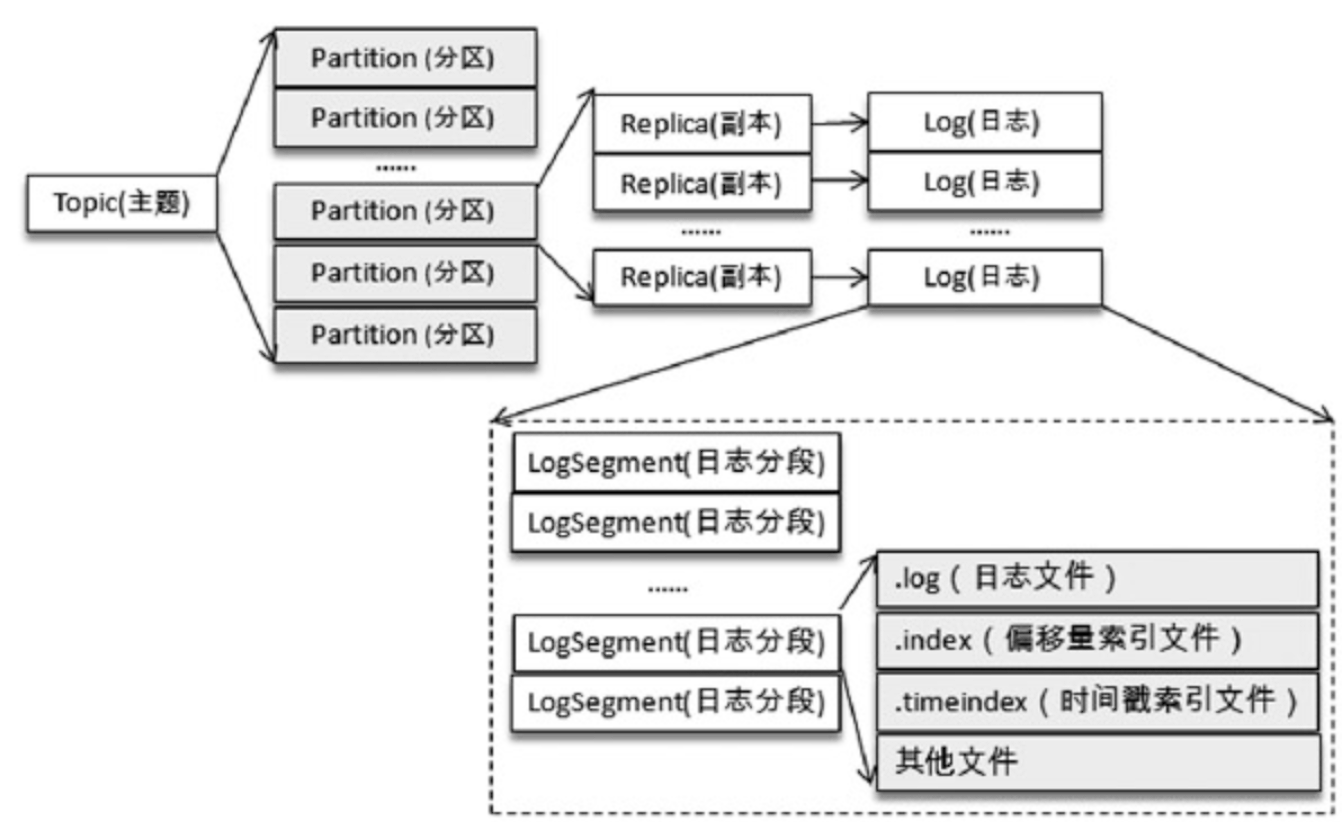
假设现在有一个test的主题,此主题中有4个分区,那么实际物理存储文件夹如下:
- test - 0
- test - 1
- test - 2
- test - 3
# 二、日志写入和消息检索
# 1、日志写入
向Log中追加消息是顺序写入的,并且只有最后LogSegment才能执行写入操作,这也一定程度提高Kafka的性能,因为写入操作都是在末尾进行的。
# 2、消息检索
每个LogSegment中的日志文件都有对应的两个索引文件:
- 偏移量索引文件(.index后缀)
- 时间戳索引文件(.timeindex后缀)
每个LogSegment都有一个基准偏移量baseOffset,用来表示当前LogSegment中第一条消息的offset,比如现在第二个LogSegment文件目录如下:
- 00000000000000000133.index
- 00000000000000000133.log
- 00000000000000000133.timeindex
说明这个LogSegment中的第一条消息偏移量为133,也说明上一个LogSegment共有133条消息(偏移量从0到132)
# 三、日志格式
# 1、消息压缩
常见压缩算法是文件越大,压缩效果越好,由于kafka中一条消息不会太大,为了让压缩效果越好,kafka是通过多条消息进行压缩的。
消息压缩时是将整个消息集进行压缩作为内层消息,内层消息整体作为外层的value:
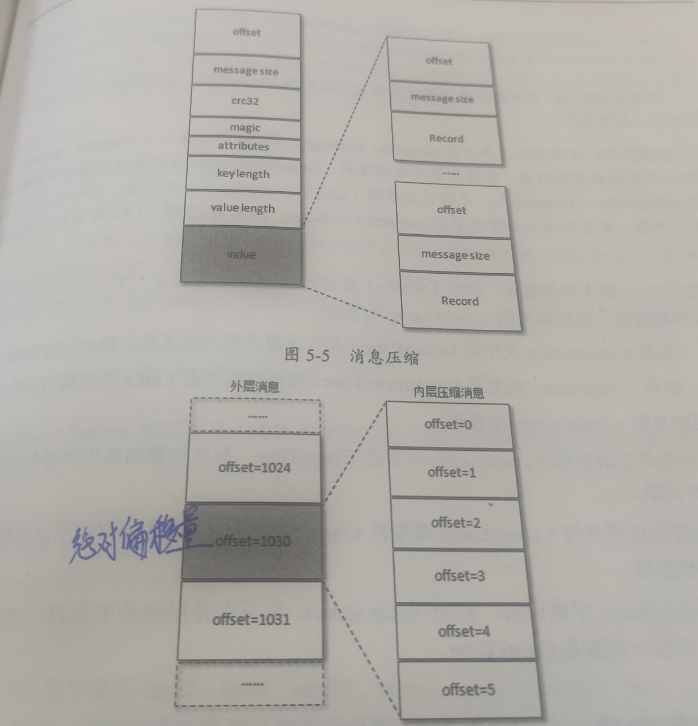
外层消息保存了内层消息中最后一条消息的绝对位移,绝对位移是相对整个分区而言的。
# 2、V2版本
v2版本的消息集为Record Batch,内部包含了一条或多条消息,其中first offset到records count的部分是不被压缩的,而是压缩records字段中的所有内容。
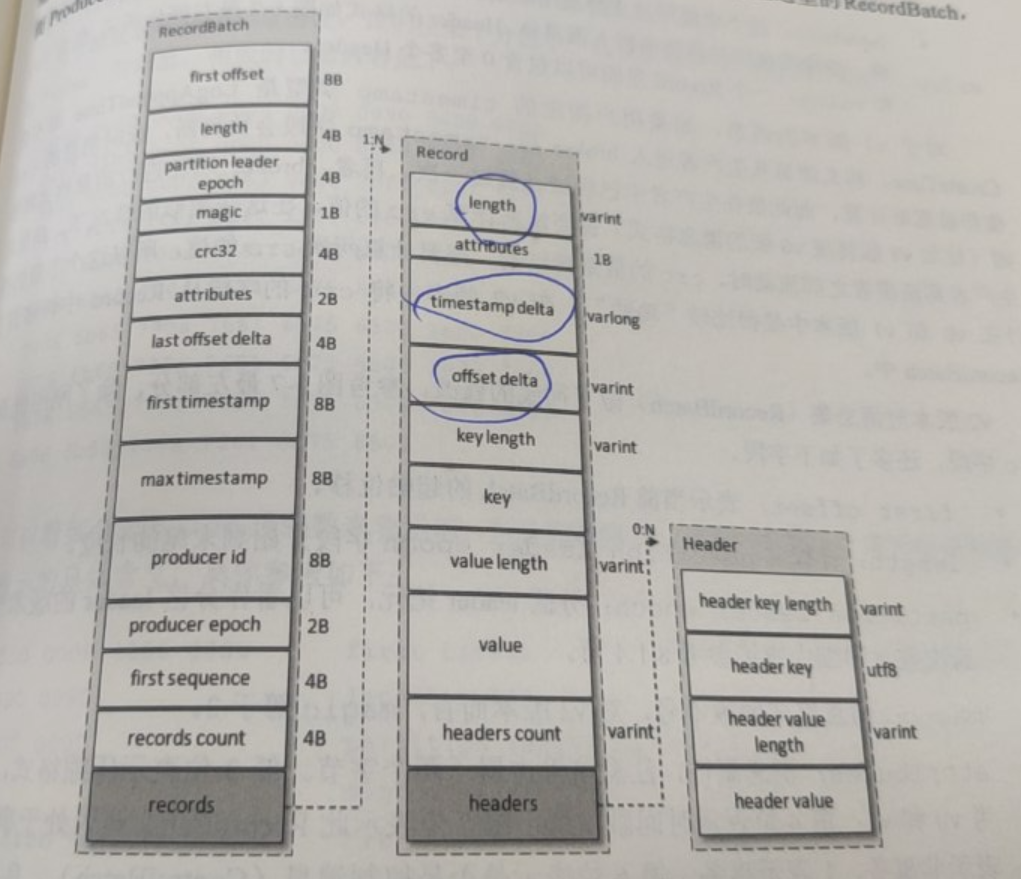
RecordBatch
- first offset:当前RecordBatch的初始位移
- length:计算从partition leader epoch字段开始到末尾的长度
- partition leader epoch:分区leader的版本号或更新次数
- magic:消息格式的版本号
- attributes:消息属性
- 低三位表示压缩格式
- 第四位表示时间戳类型
- 第五位表示此RecordBatch是否处于事务中
- 第六位是否控制消息
Records
- length:消息总长度
- attributes:弃用
- timestamp delta:时间戳增量
- offset delta:位移增量
# 3、日志索引
每个日志分段文件对应了两个索引文件,主要用于提高查找消息的效率:
- 偏移量索引文件用来建立消息偏移量(offset)到物理地址的映射关系
- 时间戳索引文件则根据指定的时间戳来查找对应的偏移量索引
Kafka中的索引文件以稀疏索引的方式构造消息的索引,并不保证每个消息在索引文件都有对应的索引项:
- 对于偏移量索引,由于是单调递增的,查询指定偏移量就可以采用二分法进行快速定位
- 对于时间戳索引,也是保存单调递增的,同样可以采用二分法进行定位
# 3.1 偏移量索引
偏移量索引项的格式如下图所示,每个索引项占用8个字节:
- relativeOffset:相对偏移量,表示消息相对于baseOffset的偏移量,占用四个字节
- position:物理地址,消息在日志分段中对应的物理位置
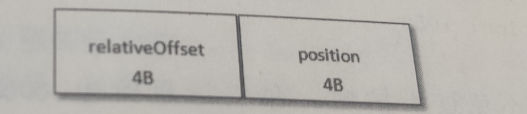
其中索引项使用相对偏移量,没有使用绝对偏移量是为了减少索引占用的空间,例如一个日志分段的baseOffset为32,那么offset为35的相对偏移量就是:35 - 32 = 3
# 3.2 时间戳索引
时间戳索引文件中包含若干个时间戳索引项,同时需要保证每个追加的时间戳索引项中的timestamp必须大于之前追加的索引项的timestamp。
- timestamp:当前日志分段最大的时间戳
- ralativeOffset: 时间戳对应的消息的相对偏移量

# 四、日志清理
Kafka将消息存储在磁盘中,为了控制磁盘占用空间的不断就需要对消息进行一个清理操作,并且Kakfa分区中的每一个副本都对应一个Log,而每个Log是分多个日志段,这样也是利于日志操作的。
- 日志删除:按照一定的保留策略直接删除不符合条件的日志分段
- 日志压缩:针对每个消息的key进行整合,对于有相同key的不同value值,只保留最后一个版本
# 1、日志删除
在kafka日志管理器中会有一个专门的日志删除任务来周期性地监测和删除不符合保留条件的日志分段文件,这个周期默认是30000,就是5分钟。而日志分段的保留策略有三种:
- 基于时间
- 基于日志大小
- 基于日志起始偏移量的保留策略
基于时间
日志删除任务会检查当前日志文件中是否有保留时间超过设定的阈值来寻找可删除的日志分段文件集合,这个日志分段的保留时间默认为7天。
基于日志大小
日志删除任务会检查当前日志文件中是否有日志大小超过阈值来寻找可删除的日志分段的文件集合
基于日志起始偏移量的保留策略
判断依据是根据某日志分段的下一个日志分段的起始偏移量baseOffset是否小于等于logStartOffset
# 2、日志压缩
对于有相同key的不同value值,只保留最后一个版本。如果应用只关心key对应的最新值value值,则可以开启kafka的日志清理功能。
# 五、磁盘存储
kafka依赖于文件系统来存储和缓存消息,但是基于我们的认知磁盘速度是比较慢的,那么kafka是如何提供高性能读写能力呢?
# 1、顺序读写
kafka在设计时采用了文件追加的方式来写入消息,即只能在日志文件的尾部追加新的消息,并且也不允许修改已写入的消息,是典型的顺序写盘的操作。
# 2、页缓存
页缓存是操作系统实现的一中主要的磁盘缓存,以此来减少对磁盘的I/O操作。具体来说,就是把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问。
不建议使用同步刷盘来提高消息的可靠性,因为这会严重影响性能,消息的可靠性应该由多副本机制来保证。
# 3、零拷贝
所谓的零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手,减少内核和用户模式之间的上下文切换。
# 六、何时压缩
在kafka中,消息压缩可能会发生在两个地方生产端和broker端
# 1、生产端
生产者程序中配置compression.type参数即表示启用指定类型的压缩算法:
// 开启GZIP压缩
props.put("compression.type", "gzip");
表明该 Producer 的压缩算法使用的是 GZIP。这样 Producer 启动后生产的每个消息集合都是经 GZIP 压缩过的,故而能很好地节省网络传输带宽以及 Kafka Broker 端的磁盘占用。
# 2、broker端
大部分情况下 Broker 从 Producer 端接收到消息后仅仅是原封不动地保存而不会对其进行任何修改,有两种特殊情况会进行重写压缩消息:
- Broker 端指定了和 Producer 端不同的压缩算法
- Broker 端发生了消息格式转换
# 七、何时解压缩
有压缩必有解压缩!通常来说解压缩发生在消费者程序中,也就是说 Producer 发送压缩消息到 Broker 后,Broker 照单全收并原样保存起来。然后Consumer自行解压缩还原成之前的消息。
从生产到消息整体流程:Producer 端压缩、Broker 端保持、Consumer 端解压缩。