 生产者客户端开发
生产者客户端开发
# 一、生产者客户端开发
# 1、生产者逻辑
- 配置生产者客户端参数及创建相应的生产者实例。
- 构建待发送的消息。
- 发送消息。
- 关闭生产者实例。
# 2、配置优化
针对我们的Properties配置,我们可以采用配置文件的方式或者静态实例的方式来进行加载。
静态实例
public static Properties initConfig(){
Properties props = new Properties();
props.put("bootstrap.servers", brokerList);
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("client.id", "producer.client.id.demo");
return props;
}
配置文件
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
retries: 0
batch-size: 16384
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
bootstrap.servers:该参数用来指定生产者客户端连接 Kafka 集群所需的 broker 地址清单,具体的内容格式为 host1:port1,host2:port2,可以设置一个或多个地址,中间以逗号隔开,此参数的默认值为“”。key.serializer和value.serializer:这两个参数分别用来指定 key 和 value 序列化操作的序列化器。client.id:这个参数用来设定 KafkaProducer 对应的客户端id,默认值为“”。
配置key优化
实际配置过程中,key由于字符串过长,容易出错。
我们可以直接使用客户端中的 org.apache.kafka.clients.producer.ProducerConfig 类来做一定程度上的预防措施。
public static Properties initConfig(){
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.CLIENT_ID_CONFIG, "producer.client.id.demo");
return props;
}
# 3、消息对象
在发送消息之前,我们要进行消息对象的构建:
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, "hello, Kafka!");
发送的消息对象包括记录要发送到的主题名称、可选的分区号以及可选的键和值。
public class ProducerRecord<K, V> {
private final String topic; //主题
private final Integer partition; //分区号
private final Headers headers; //消息头部
private final K key; //键
private final V value; //值
private final Long timestamp; //消息的时间戳
//省略其他成员方法和构造方法
}
- 主题:消息的分类。
- 分区号:
- 如果指定了有效的分区号,则在发送记录时将使用该分区。
- 如果没有指定分区,但有一个键,则会使用键的散列选择分区。
- 如果键和分区都不存在,分区将以循环方式分配。
- Key:是用来指定消息的键,它不仅是消息的附加信息,还可以用来计算分区号进而可以让消息发往特定的分区。
- value:消息的内容。
# 4、消息发送
发送消息的方法,其中topic和value是必须的:
public ProducerRecord(String topic, Integer partition, Long timestamp,
K key, V value, Iterable<Header> headers)
public ProducerRecord(String topic, Integer partition, Long timestamp,
K key, V value)
public ProducerRecord(String topic, Integer partition, K key, V value,
Iterable<Header> headers)
public ProducerRecord(String topic, Integer partition, K key, V value)
public ProducerRecord(String topic, K key, V value)
public ProducerRecord(String topic, V value)
创建生产者实例和构建消息之后,就可以开始发送消息了。发送消息主要有三种模式:
- 发后即忘(fire-and-forget)
- 同步(sync)
- 异步(async)
发后即忘
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, "hello, Kafka!");
try {
producer.send(record);
} catch (Exception e) {
e.printStackTrace();
}
producer.close();
这种就是典型的发后即忘模式,只管往 Kafka 中发送消息而并不关心消息是否正确到达,有如下特点:
- 性能高
- 可靠性差
同步方式
public Future<RecordMetadata> send(ProducerRecord<K, V> record)
try {
producer.send(record).get();
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
实际上 send() 方法本身就是异步的,send() 方法返回的 Future 对象可以使调用方稍后获得发送的结果。示例中在执行 send() 方法之后直接链式调用了 get() 方法来阻塞等待 Kafka 的响应,直到消息发送成功,或者发生异常。如果发生异常,那么就需要捕获异常并交由外层逻辑处理。
如果要获取消息的一些元数据信息,可以采用如下方式:
try {
Future<RecordMetadata> future = producer.send(record);
RecordMetadata metadata = future.get();
System.out.println(metadata.topic() + "-" +
metadata.partition() + ":" + metadata.offset());
} catch (ExecutionException | InterruptedException e) {
e.printStackTrace();
}
同步的发送方式有如下特点:
- 同步发送的方式可靠性高,要么消息被发送成功,要么发生异常。如果发生异常,则可以捕获并进行相应的处理。
- 同步发送的方式性能会差很多,需要阻塞等待一条消息发送完之后才能发送下一条。
异常处理
KafkaProducer 中一般会发生两种类型的异常:
- 可重试的异常:
- 不可重试的异常:
对于可重试的异常,如果配置了 retries 参数,那么只要在规定的重试次数内自行恢复了,就不会抛出异常。retries 参数的默认值为0,配置方式参考如下:
props.put(ProducerConfig.RETRIES_CONFIG, 10);
异步
send() 方法的返回值类型就是 Future,而 Future 本身就可以用作异步的逻辑处理。
但是由于这个方法可以随时调用get方法,以及怎么调用都是需要面对的问题,消息不停地发送,那么诸多消息对应的 Future 对象的处理难免会引起代码处理逻辑的混乱。
因此采用Callback 的方式非常简洁明了,Kafka 有响应时就会回调,要么发送成功,要么抛出异常。
public static void main(String[] args) {
Properties properties = initConfig();
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, "hello, Kafka!");
try {
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println(metadata.topic() + "-" +
metadata.partition() + ":" + metadata.offset());
}
});
} catch (Exception e) {
e.printStackTrace();
}
producer.close();
}
回调函数中有两个参数:
- RecordMetadata:消息元数据,可以获得主题、位移量等
- Exception:异常
回调的先后顺序
假设我们发送了两条消息,代码如下:
producer.send(record1, callback1);
producer.send(record2, callback2);
对于同一个分区而言,如果消息 record1 于 record2 之前先发送,那么 KafkaProducer 就可以保证对应的 callback1 在 callback2 之前调用,也就是说,回调函数的调用也可以保证分区有序。
# 5、资源回收
在日常业务需求中,KafkaProducer可能会发送好几条消息,在发送完这些消息之后,需要调用 KafkaProducer 的 close() 方法来回收资源。
producer.close();
这个无参close方法,阻塞等待之前所有的发送请求完成后再关闭 KafkaProducer。
对应有一个带有参数的close方法:
public void close(long timeout, TimeUnit timeUnit)
如果调用了带超时时间 timeout 的 close() 方法,那么只会在等待 timeout 时间内来完成所有尚未完成的请求处理,然后强行退出。
在实际应用中,一般使用的都是无参的 close() 方法。
# 二、序列化-分区器-拦截器
客户端消息在真正发送到Broker,还会经历三个过程:
- 序列化:需要把对象转化为二进制流的方式
- 分区器:如果没有指定分区,就需要根据 key 这个字段来计算 partition 的值。分区器的作用就是为消息分配分区。
- 拦截器:在消息发送之前进行一定处理
# 1、序列化
在之前的案例中,我们生产者序列化和消费者反序列化的方式如下:
public static Properties initConfig(){
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.CLIENT_ID_CONFIG, "producer.client.id.demo");
return props;
}
因为我们发送和接受都是String,所以我们采用的StringSerializer序列化。
Kafka有许多序列化器,但是他们都实现了Serializer<T>接口:
public interface Serializer<T> extends Closeable {
default void configure(Map<String, ?> configs, boolean isKey) {
// intentionally left blank
}
byte[] serialize(String topic, T data);
default byte[] serialize(String topic, Headers headers, T data) {
return serialize(topic, data);
}
@Override
default void close() {
// intentionally left blank
}
}
通常而言,还是采用Json进行序列化和反序列化操作。
# 2、分区器
消息经过序列化之后就需要确定它发往的分区,如果消息 ProducerRecord 中指定了 partition 字段,那么就不需要分区器的作用,因为 partition 代表的就是所要发往的分区号。
如果消息 ProducerRecord 中没有指定 partition 字段,那么就需要依赖分区器,根据 key 这个字段来计算 partition 的值。分区器的作用就是为消息分配分区。
Kafka的分区器都实现了Partitioner接口:
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster);
public void close();
其中 partition() 方法用来计算分区号,返回值为 int 类型。
partition() 方法中的参数:
topic:主题、
Key:键
keyBytes:序列化后的键
value:值
valueBytes:序列化后的值
cluster:当前集群元数据
如果我们要根据业务去实现一个特殊的分区器,只需要实现这个接口,然后配置即可:
public class DemoPartitioner implements Partitioner {
private final AtomicInteger counter = new AtomicInteger(0);
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
// todo
return 0;
}
@Override public void close() {}
@Override public void configure(Map<String, ?> configs) {}
}
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,
DemoPartitioner.class.getName());
# 3、生产拦截器
生产者拦截器既可以用来在消息发送前做一些准备工作,比如按照某个规则过滤不符合要求的消息、修改消息的内容等,也可以用来在发送回调逻辑前做一些定制化的需求,比如统计类工作。
生产者拦截器需要实现ProducerInterceptor 接口:
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record);
public void onAcknowledgement(RecordMetadata metadata, Exception exception);
public void close();
KafkaProducer 在将消息序列化和计算分区之前会调用生产者拦截器的 onSend() 方法来对消息进行相应的定制化操作。
KafkaProducer 会在消息被应答(Acknowledgement)之前或消息发送失败时调用生产者拦截器的 onAcknowledgement() 方法,优先于用户设定的 Callback 之前执行。
案例实现
我们有如下业务:需要在发送的信息之前添加test前缀,并记录发送成功多少条,发送失败多少条。
一般来说最好不要修改消息 ProducerRecord 的 topic、key 和 partition 等信息。
拦截器代码:
public class TestInterceptorPrefix implements ProducerInterceptor {
private volatile long sendSuccess = 0;
private volatile long sendFailure = 0;
@Override
public ProducerRecord onSend(ProducerRecord record) {
String modifiedValue = "test-" + record.value();
return new ProducerRecord<>(record.topic(),
record.partition(), record.timestamp(),
record.key(), modifiedValue, record.headers());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (exception == null) {
sendSuccess++;
} else {
sendFailure ++;
}
}
@Override
public void close() {
System.out.println("发送成功次数:" + sendSuccess);
System.out.println("发送成功次数:" + sendFailure);
}
@Override
public void configure(Map<String, ?> configs) {
}
}
配置
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
TestInterceptorPrefix.class.getName());
输出
// 生产者
发送成功次数:10
发送成功次数:0
// 消费者
test-Kafka
test-Kafka
test-Kafka
test-Kafka
test-Kafka
test-Kafka
test-Kafka
test-Kafka
test-Kafka
test-Kafka
拦截链
KafkaProducer 中不仅可以指定一个拦截器,还可以指定多个拦截器以形成拦截链。拦截链会按照 interceptor.classes 参数配置的拦截器的顺序来。
配置的时候,各个拦截器之间使用逗号隔开。
现在我们额外配置一个拦截器:
public class TestPlusInterceptorPrefix implements ProducerInterceptor {
@Override
public ProducerRecord onSend(ProducerRecord record) {
String modifiedValue = "testPlus-"+record.value() ;
return new ProducerRecord<>(record.topic(),
record.partition(), record.timestamp(),
record.key(), modifiedValue, record.headers());
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
拦截器链配置
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
TestInterceptorPrefix.class.getName() + "," + TestPlusInterceptorPrefix.class.getName());
消费者输出
testPlus-test-Kafka
在拦截链中,如果某个拦截器执行失败,那么下一个拦截器会接着从上一个执行成功的拦截器继续执行。所以对于A和B拦截器,如果B拦截器依赖于A拦截器逻辑处理,这个时候如果A执行失败,那么B仍然会进行执行,相关逻辑就会出现问题。
# 三、生产者客户端发送原理
整个生产者客户端由两个线程协调运行,这两个线程分别为主线程和 Sender 线程(发送线程)。
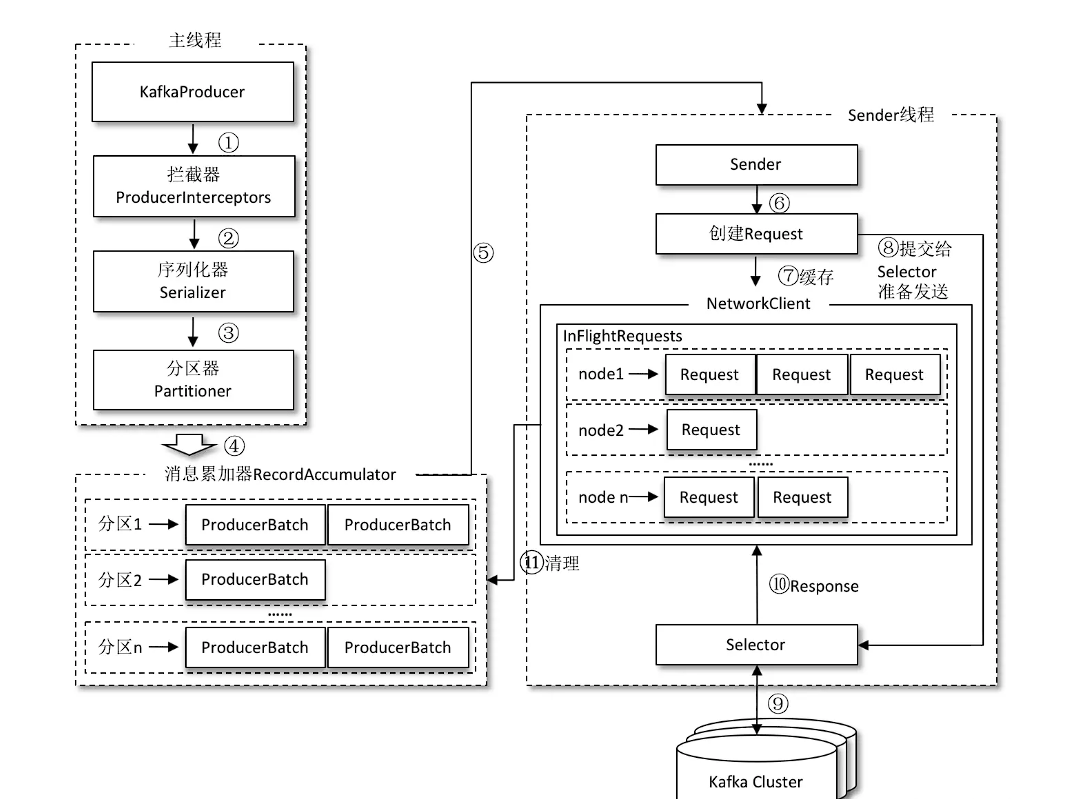
# 1、拦截器-序列化器-分区器
- 拦截器:发送消息之前进行额外的处理。
- 序列化器:将对象序列化为字节数组。
- 分区器:按照一定规则把消息送往对应分区。
# 2、RecordAccumulator
主要作用
主要用来缓存消息以便 Sender 线程可以批量发送,进而减少网络传输的资源消耗以提升性能。
如果生产者发送消息的速度超过发送到服务器的速度,则会导致生产者空间不足,这个时候 KafkaProducer 的 send() 方法调用要么被阻塞,要么抛出异常,这个取决于参数 max.block.ms 的配置,此参数的默认值为60000,即60秒。
内部原理
RecordAccumulator内部为每个分区都维护了一个双端队列,队列中的内容就是 ProducerBatch,即 Deque。
消息写入的时候,追加到队列,消息读取从队头读取。
ProducerBatch 不是 ProducerRecord,ProducerBatch 中可以包含一至多个 ProducerRecord,通过这样减少网络请求的次数以提升整体的吞吐量
- ProducerRecord:发送的一个消息
- ProducerBatch:发送的一个消息批次,包含多个消息
内部流程
- 判断是否存在双端队列,如果没有则创建,如果有就入队
- 从队列的末尾获取ProducerBatch,如果没有创建
- 判断ProducerBatch是否还能够加入,如果不能够加入,创建新的ProducerBatch
# 3、Sender
分区转broker
对于客户端Producer:只关心发送到那个分区
对于网络连接:只关心发送到那个具体broker
所以,Sender 从 RecordAccumulator 中获取缓存的消息之后,会进一步将原本<分区, Deque< ProducerBatch>> 的保存形式转变成 <Node, List< ProducerBatch> 的形式。需要做一个应用逻辑层面到网络I/O层面的转换。
封装Request
在转换成 <Node, List> 的形式之后,Sender 还会进一步封装成 <Node, Request> 的形式,这样就可以将 Request 请求发往各个 Node 了,这里的 Request 是指 Kafka 的各种协议请求,对于消息发送而言就是指具体的 ProduceRequest。