 高水位和Leader Epoch
高水位和Leader Epoch
# 一、高水位定义和流程
# 1、定义
Kafka 的水位不是时间戳,更与时间无关。它是和位置信息绑定的,具体来说,它是用消息位移来表征的。即用来标识分区下的哪些消息是可以被消费者消费的。
# 2、流程
生产者一直往leader副本中写入消息,某一时刻,leader副本的LEO增加到5,并且带有自身的HW信息。
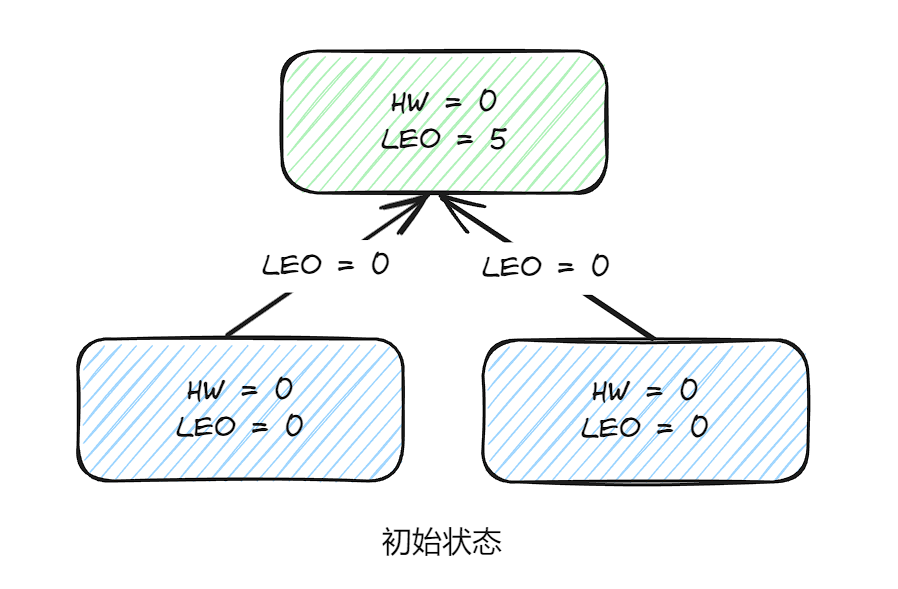
此时两个follower副本各自拉取到了消息,并更新各自的LEO为3和4,follower副本还会更新自己的HW,更新HW的算法:min(HW,LEO)。
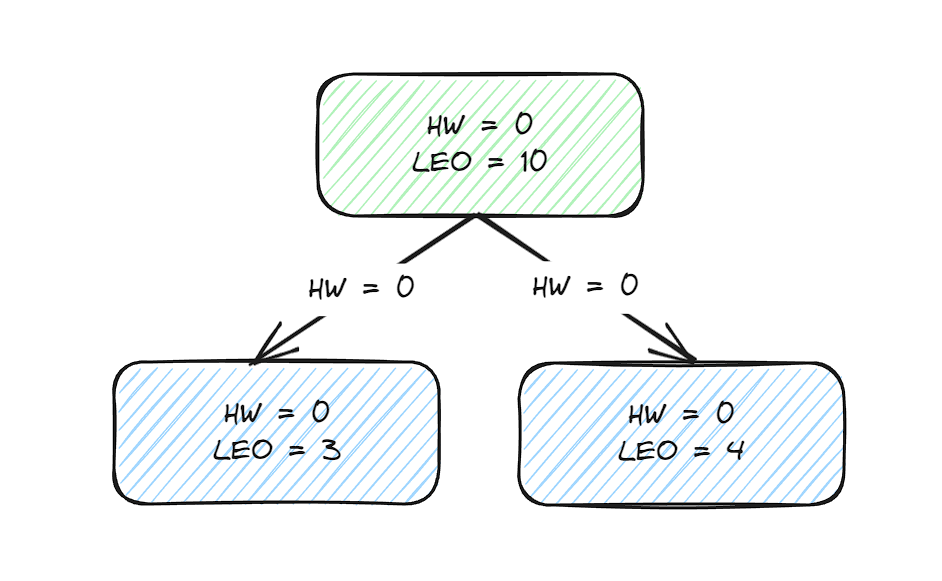 接下来follower副本再次请求leader副本的消息,leader副本的HW计算方式是:min(15, 3, 4) = 3
接下来follower副本再次请求leader副本的消息,leader副本的HW计算方式是:min(15, 3, 4) = 3
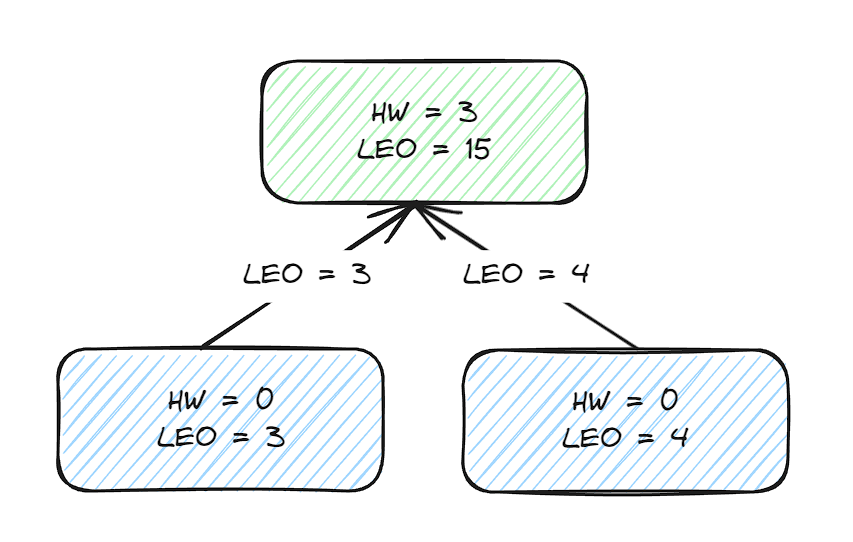
两个follower副本在收到新的消息之后更新LEO并且更新自己的HW为3,min(LEO, 3) = 3
# 二、高水位作用
在 Kafka 中,高水位的作用主要有 2 个:
- 定义消息可见性,即用来标识分区下的哪些消息是可以被消费者消费的。
- 帮助 Kafka 完成副本同步。
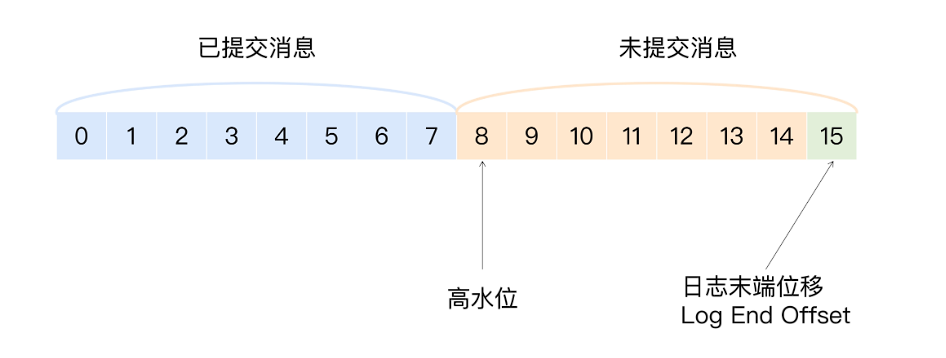
高水位以下的消息被认为是已提交的消息,反之就是未提交的消息,也就是说消费者只能消费到高水位之下的消息。
位移值等于高水位的消息也属于未提交消息。也就是说,高水位上的消息是不能被消费者消费的。
日志末端位移表示副本写入下一条消息的位移值,这也表示同一个副本对象,其高水位值不会大于 LEO 值。
高水位和 LEO 是副本对象的两个重要属性。Kafka 所有副本都有对应的高水位和 LEO 值,而不仅仅是 Leader 副本。只不过 Leader 副本比较特殊,Kafka 使用 Leader 副本的高水位来定义所在分区的高水位。换句话说,分区的高水位就是其 Leader 副本的高水位。
# 三、Leader Epoch
依托于高水位,Kafka 既界定了消息的对外可见性,又实现了异步的副本同步机制。不过,我们还是要思考一下这里面存在的问题。
# 1、高水位问题
数据丢失
现在假设有一个副本A(follower副本),副本B(Leader副本),由于HW的同步是存在间隔的,此时A副本的HW为1,B副本的HW为2。
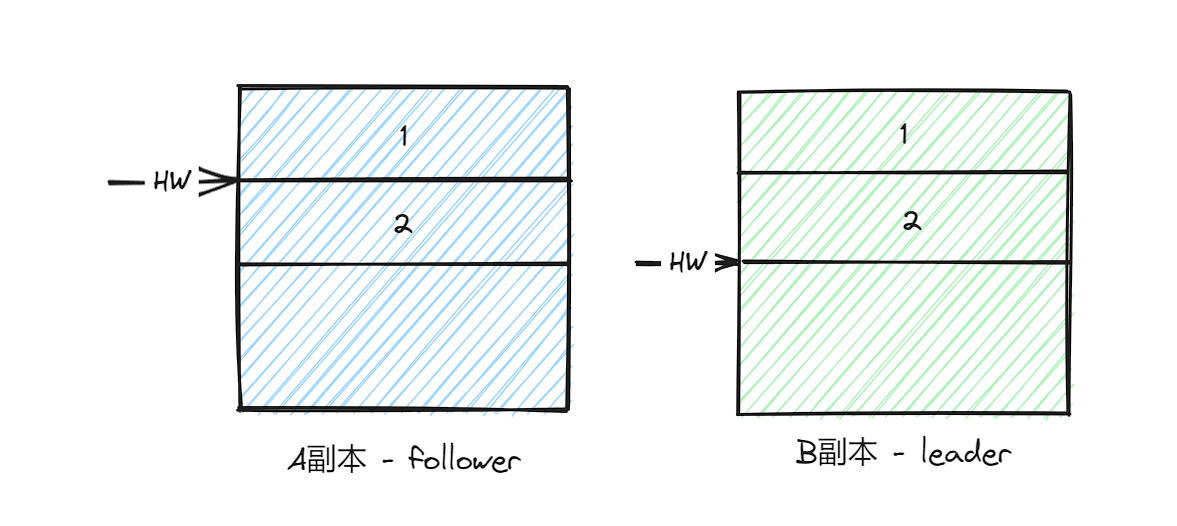
此时如果A副本宕机重启,由于HW为1,所以会截断消息2:
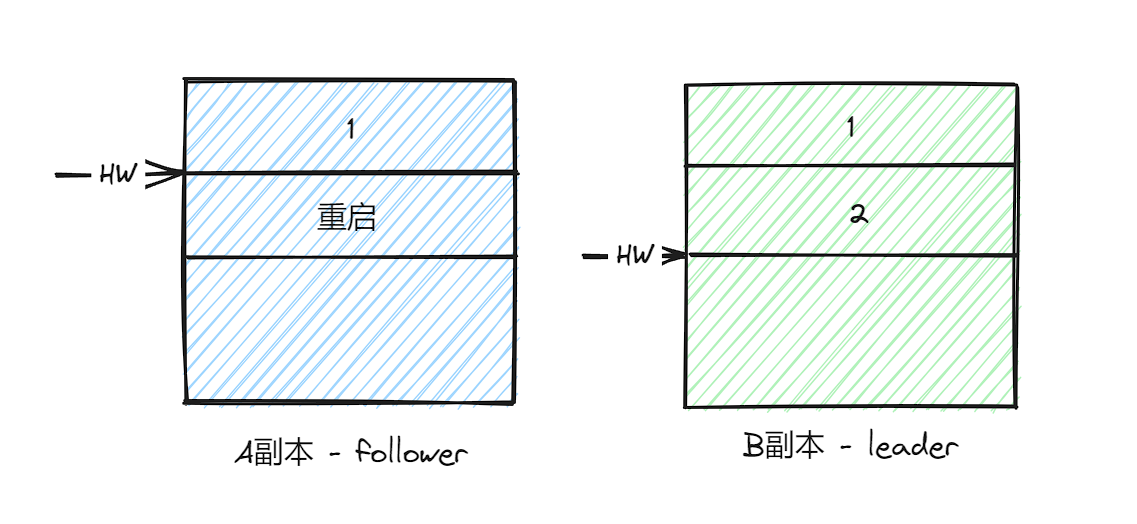
A重启之后,会给B副本发出同步请求,如果这个时候B副本也宕机了,那么A副本就成为leader副本,B恢复之后成为follower副本,由于follower副本HW不能比leader副本的HW高,所以会把消息2截断,这样的消息2就丢失了。
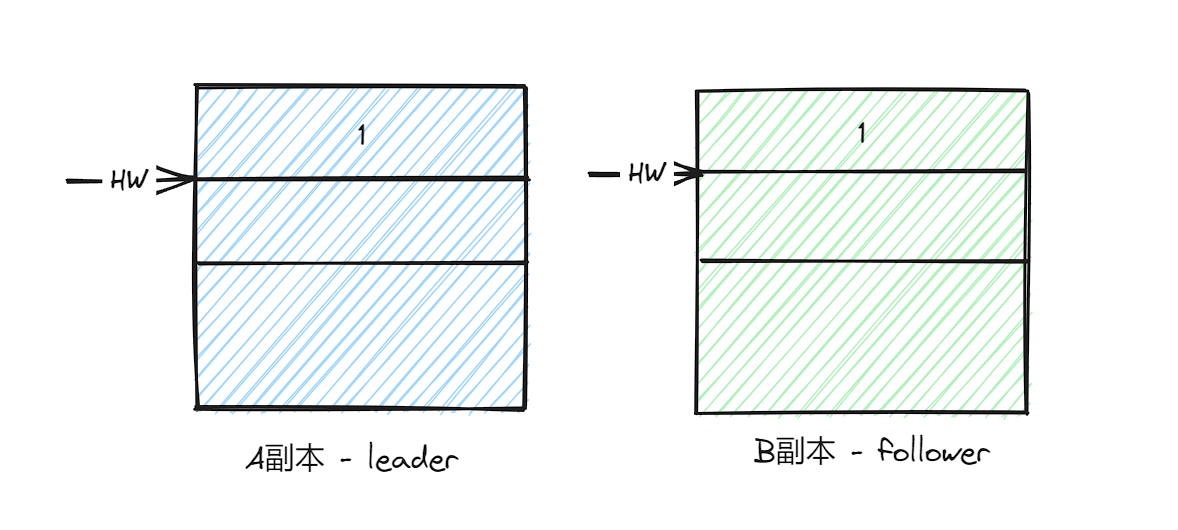
数据不一致
当前leader副本为A,follower副本为B,A中有两条消息,并且HW和LEO都为2,B中有一条消息,HW和LEO都为1:
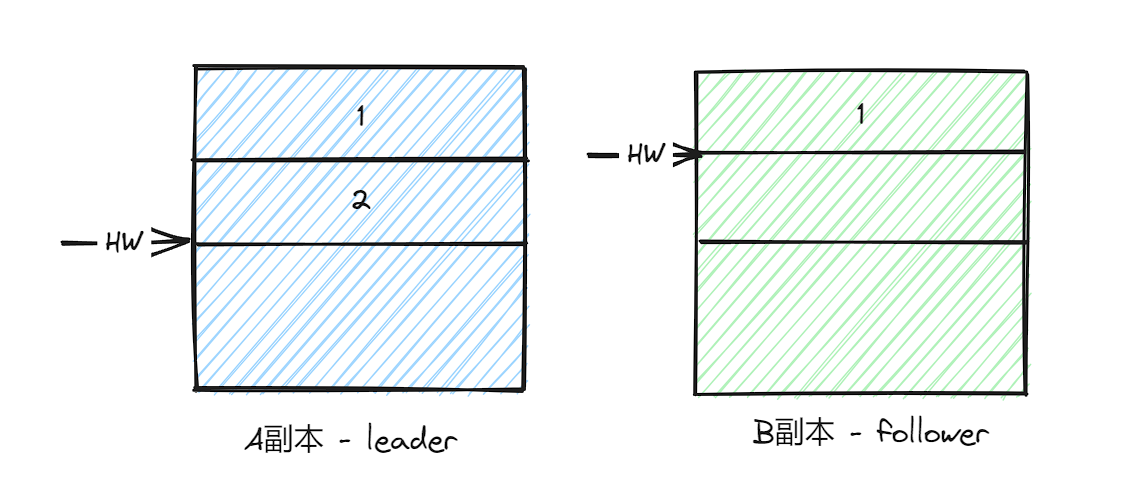
现在假设A副本和B副本同时宕机,并且B副本最先恢复过来,成为Leader副本,然后写入消息3,并且将LEO和HW更新为2。
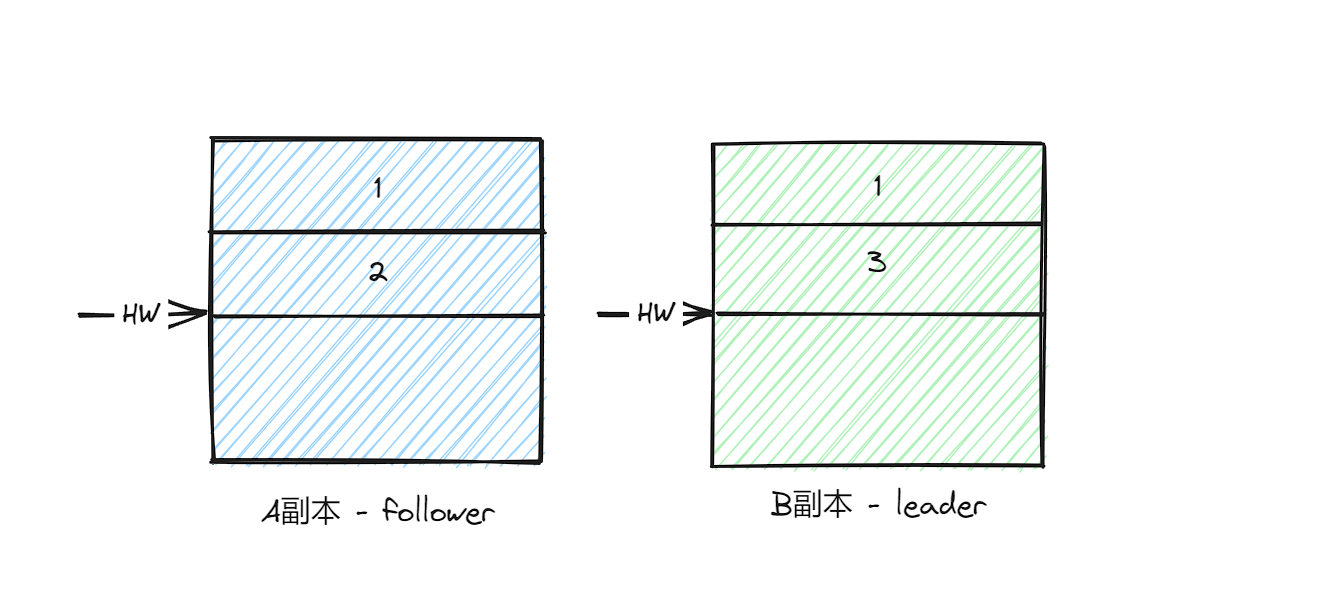
这个时候就出现了数据不一致的情况。
# 2、Leader Epoch组成
- Epoch。一个单调增加的版本号。每当副本领导权发生变更时,都会增加该版本号。小版本号的 Leader 被认为是过期 Leader,不能再行使 Leader 权力。
- 起始位移(Start Offset)。Leader 副本在该 Epoch 值上写入的首条消息的位移。
假设现在有两个 Leader Epoch<0, 0> 和 <1, 120>,那么第一个 Leader Epoch 表示版本号是 0,这个版本的 Leader 从位移 0 开始保存消息,一共保存了 120 条消息。之后,Leader 发生了变更,版本号增加到 1,新版本的起始位移是 120。
# 3、Leader Epoch如何解决高水位问题
数据丢失
数据不一致