 Java集合
Java集合
# Java集合概念
List(对付顺序的好帮手): 存储的元素是有序的、可重复的。Set(注重独一无二的性质):存储的元素是无序的、不可重复的。Queue(实现排队功能的叫号机): 按特定的排队规则来确定先后顺序,存储的元素是有序的、可重复的。Map(用 key 来搜索的专家):使用键值对(key-value)存储,类似于数学上的函数 y=f(x),"x" 代表 key,"y" 代表 value,key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
# Java集合-List
# ArrayList扩容机制
# 构造函数
基础属性
/**
* 默认初始容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 用于空实例的共享空数组实例。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
构造方法一
构造一个具有指定初始容量的空列表。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
// 如果传入的初始容量大于0,就新建一个数组存储元素
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 如果传入的初始容量等于0,使用空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
// 如果传入的初始容量小于0,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
构造方法二
构造一个初始容量为 10 的空列表。
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
构造方法三
public ArrayList(Collection<? extends E> c) {
// 集合转数组
Object[] a = c.toArray();
// 非空集合
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else { // 空集合
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
# 添加元素方法
添加一个元素到集合的尾部
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
检查是否需要扩容:
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
# 扩容
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 新容量等于旧容量加上旧容量右移一位,也就是1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果新容量还是不够
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量已经超过最大容量了,则使用最大容量
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
扩容操作实际上是调用Arrays.copyOf()把原数组拷贝为一个新数组,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
# ArrayList和Vector的区别
ArrayList 是 List 的主要实现类,底层使用 Object[ ]存储,适用于频繁的查找工作,线程不安全;
Vector 是 List 的古老实现类,底层使用 Object[ ]存储,线程安全的
# ArrayList和LinkedList的区别
是否保证线程安全: ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
底层数据结构: Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是 双向链表 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
插入和删除是否受元素位置的影响:
① ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。 比如:执行add(E e)方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(add(int index, E element))时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。
② LinkedList 采用链表存储,所以对于add(E e)方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置i插入和删除元素的话((add(int index, E element)) 时间复杂度近似为o(n))因为需要先移动到指定位置再插入。
是否支持快速随机访问: LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于get(int index)方法)。
内存空间占用: ArrayList 的空间浪费主要体现在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)
# ArrayList能够实现什么数据结构
1、队列
2、List
3、链表
4、双向链表
5、环形链表
# Java集合-Set
# HashSet、LinkedHashSet 和 TreeSet 三者的异同
HashSet、LinkedHashSet和TreeSet都是Set接口的实现类,都能保证元素唯一,并且都不是线程安全的。HashSet、LinkedHashSet和TreeSet的主要区别在于底层数据结构不同。HashSet的底层数据结构是哈希表(基于HashMap实现)。LinkedHashSet的底层数据结构是链表和哈希表,元素的插入和取出顺序满足 FIFO。TreeSet底层数据结构是红黑树,元素是有序的,排序的方式有自然排序和定制排序。底层数据结构不同又导致这三者的应用场景不同。
HashSet用于不需要保证元素插入和取出顺序的场景,LinkedHashSet用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet用于支持对元素自定义排序规则的场景
# Java集合-Queue
# Queue 与 Deque 的区别
Queue 是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。
Deque 是双端队列,在队列的两端均可以插入或删除元素。
# ArrayDeque与LinkedList 的区别
ArrayDeque 和 LinkedList 都实现了 Deque 接口,两者都具有队列的功能
ArrayDeque是基于可变长的数组和双指针来实现,而LinkedList则通过链表来实现。ArrayDeque插入时可能存在扩容过程, 不过均摊后的插入操作依然为 O(1)。虽然LinkedList不需要扩容,但是每次插入数据时均需要申请新的堆空间,均摊性能相比更慢。
# PriorityQueue
PriorityQueue 是在 JDK1.5 中被引入的, 其与 Queue 的区别在于元素出队顺序是与优先级相关的,即总是优先级最高的元素先出队。
这里列举其相关的一些要点:
PriorityQueue利用了二叉堆的数据结构来实现的,底层使用可变长的数组来存储数据PriorityQueue通过堆元素的上浮和下沉,实现了在 O(logn) 的时间复杂度内插入元素和删除堆顶元素。PriorityQueue是非线程安全的,且不支持存储NULL和non-comparable的对象。PriorityQueue默认是小顶堆,但可以接收一个Comparator作为构造参数,从而来自定义元素优先级的先后。
# Java集合-Map
# HashMap
# HashMap底层
JDK1.8 之前
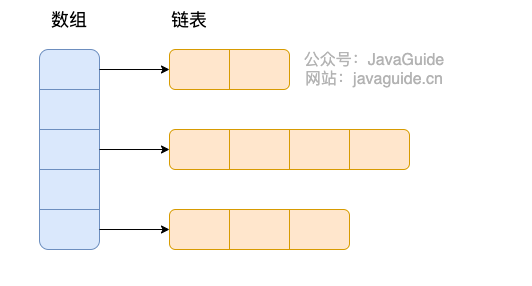
HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。HashMap 通过 key 的 hashcode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
JDK1.8 之后
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
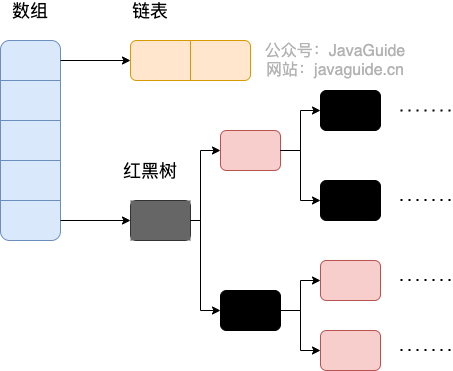
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
# 为什么要变成红黑树
因为之前的方式,链表的话,查找的时间复杂度与链表的长度相关,为 O(1 + N)。
为了降低开销,在 JAVA8 中,当链表中的元素达到 8 个,会将链表转换为红黑树,将查找的时间复杂度将为 o(1 + logN)。
# 为什么要超过一定数量之后才变成红黑树
因为红黑树类似于二叉平衡树,在插入的时候需要进行旋转,成本就比较高。
# 什么时候扩容
可以通过构造函数指定,如果没有指定,则扩容因子默认为 0.75。
当 键值对数量size > 扩容因子loadFactor * 哈希表大小 时,容器将自动扩容并重新哈希。
# 扩容机制
为什么是二次方
- 位运算,速度快,由于是位运算所以肯定是二次方。2的次数幂能够让数据更散列更均匀的分布,充分利用数组空间
- 方便链表的分裂(迭代hash),尽可能减少元素位置的移动
- 外层遍历整个哈希表
- 内层遍历哈希表上某一个单元格的链表
# ConcurrentHashMap
1.8之前
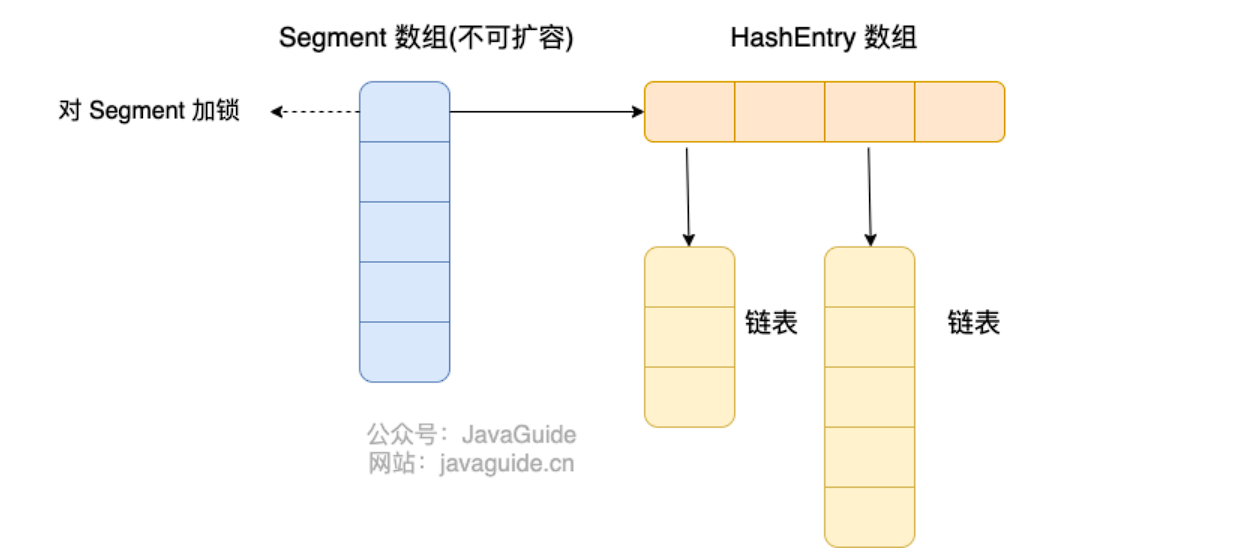
Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦初始化就不能改变,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
1.8之后
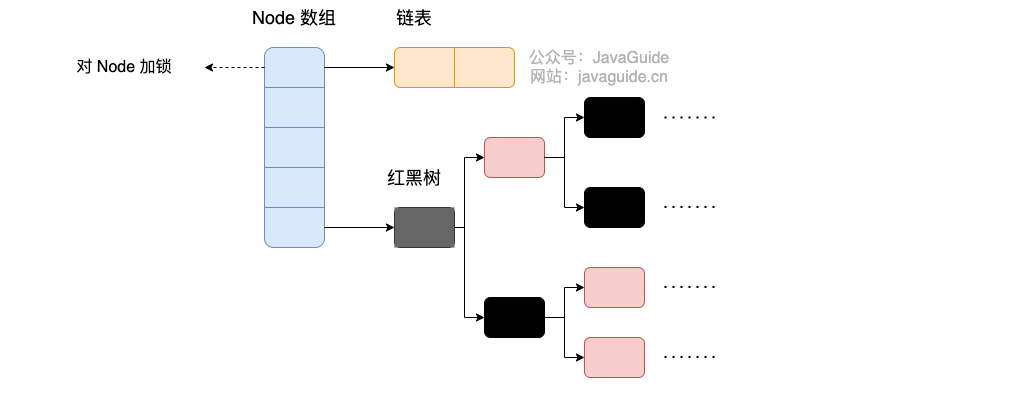
可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 Segment 数组 + HashEntry 数组 + 链表,而是 Node 数组 + 链表 / 红黑树。当冲突链表达到一定长度时,链表会转换成红黑树。